AWS 초보가 말하는 SageMaker
안녕하세요, 프로메디우스 인턴사원 간정현 입니다. 이번 포스팅에서는 AWS의 SageMaker 서비스를 소개하고 사용 후기를 공유하려고 합니다. AWS에서는 세이지메이커를 종합 관리형 머신러닝 서비스라고 소개합니다. 간단히 말해서 데이터의 제작과 전처리, 모델의 학습, 튜닝, 추론, 후처리, 배포 등의 전 과정을 쉽게 진행할 수 있도록 도와준다는 뜻입니다. 사실 제 능력이 모자라서 이 기능들을 전부 사용해보지는 못했고, 따라서 이번 포스팅은 제가 사용해본 기능들(세이지메이커 스튜디오, 훈련 작업) 위주의 편파적인 리뷰가 될 예정입니다 😅 이 점에 대해서는 양해 부탁드리고, 재미있게 봐주시면 감사하겠습니다!
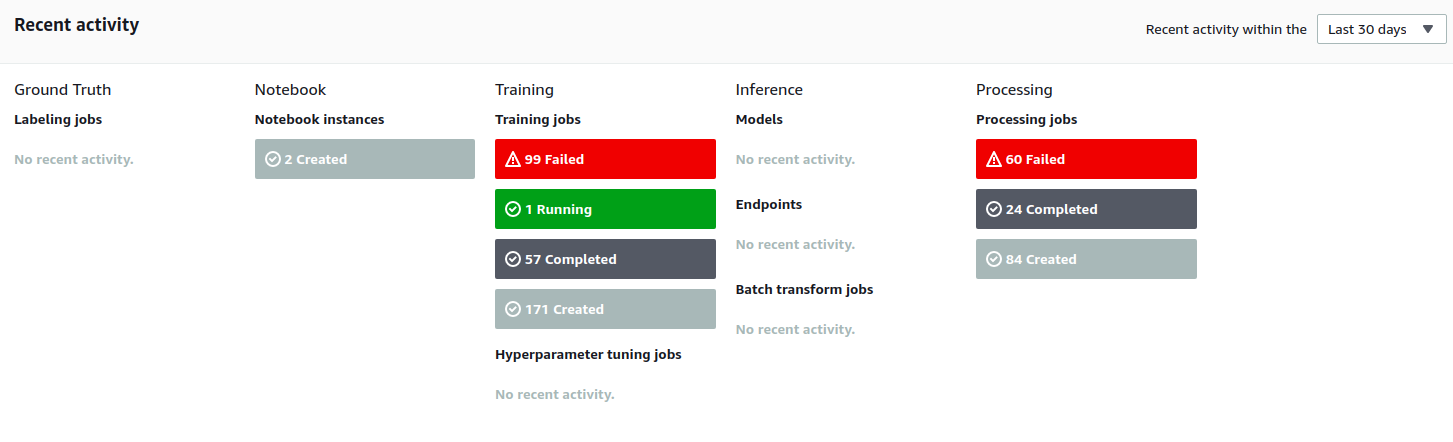
SageMaker Studio
공식 매뉴얼에 따르면 세이지메이커 스튜디오는 "동일한 애플리케이션에서 모델을 모두 빌드, 훈련, 배포 및 분석할 수 있는 통합 기계 학습 환경"이라고 합니다. 설명은 거창하지만 결국 여러 플러그인들이 포함된 주피터랩 개발환경입니다. 사실 주피터에 대한 호불호는 워낙 명확하게 갈리다 보니 여기에서 이미 세이지메이커를 사용하지 않기로 마음먹으신 분들도 계실 것 같네요 😅 저는 인터랙티브 + 마크다운이라는 컨셉이 마음에 들어서 평소에도 주피터 노트북을 자주 사용합니다. 주피터 랩은 처음 사용해봤는데 노트북에 비해 더 다양한 기능들이 통합되어있어서 익숙해지면 더 편할 것 같네요! 다만 기본적으로 제공되는 다크 테마는 코드 가독성이 매우 떨어져서 제 눈이 고생을 많이 했습니다 😵 조금 늦게 알아낸 사실이지만 Settings > Enable Extension Manager 를 체크해주면 테마 익스텐션을 설치할 수 있습니다.
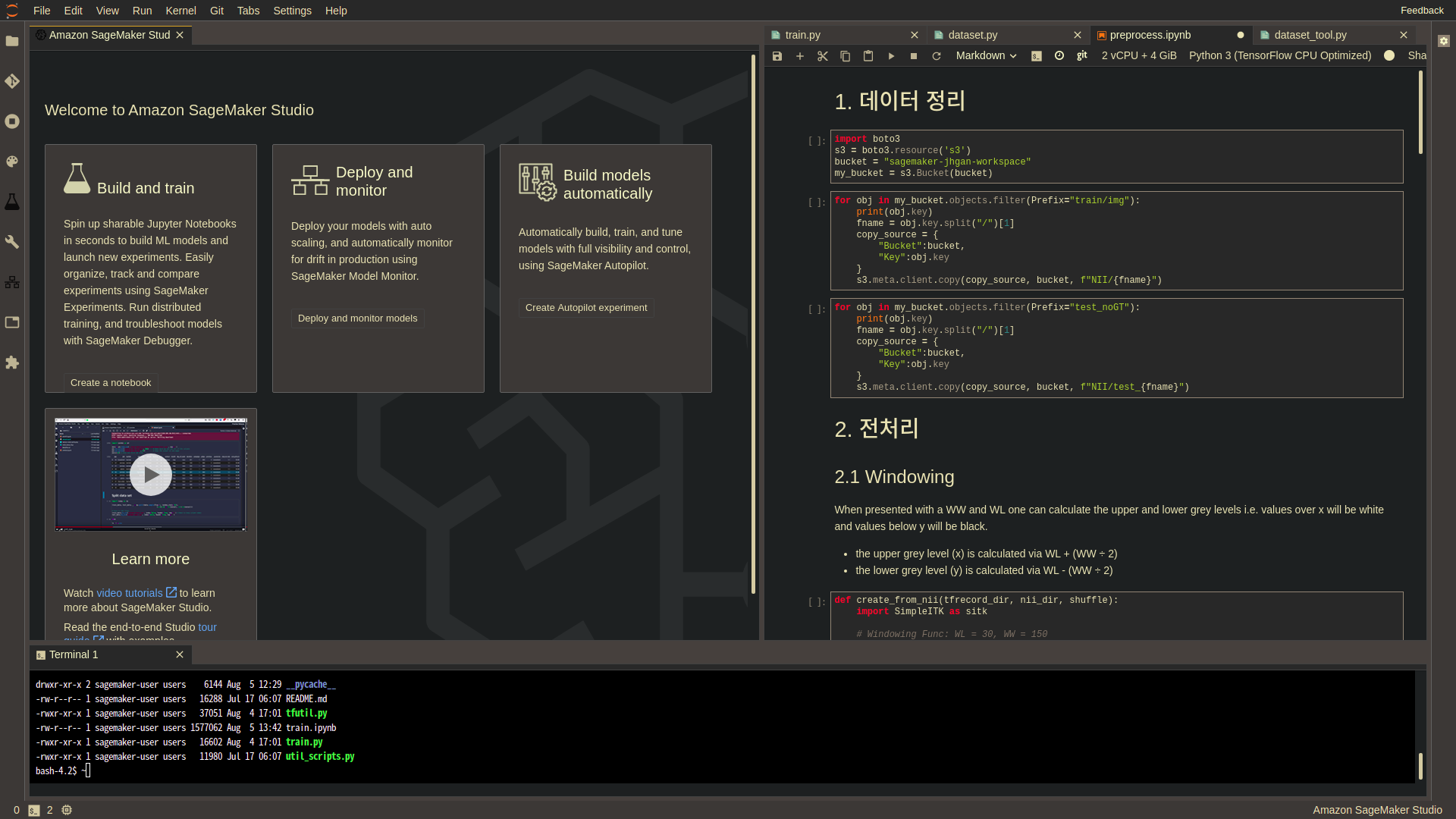
세이지메이커 스튜디오를 시작하면 원하는 이미지와 인스턴스 사양1을 골라서 커널을 띄울 수 있습니다. 텐서플로, 파이토치 등 인기있는 프레임워크를 위한 이미지들은 기본적으로 제공되기 때문에 필요한 이미지를 골라서 사용하면 됩니다. 사실 모델 학습을 위한 환경을 세이지메이커 스튜디오에 완벽하게 구축할 필요는 없습니다. 뒤에서 더 자세히 다루겠지만, 실제 모델 학습은 별도의 이미지와 인스턴스 위에서 이루어지기 때문입니다. 처음에는 이 사실을 모르고 세이지메이커 스튜디오에 완벽한 환경 세팅을 하려고 공을 들였습니다 😅 지금 생각해보면 세이지메이커 스튜디오에는 간단한 실험과 결과 분석을 위한 환경 정도만 구축해놓으면 충분한 듯 합니다.
Training Jobs
세이지메이커는 훈련 작업(training jobs)이라는 단위를 통해 모델 학습을 관리합니다. 하나의 훈련 작업은 단순히 '코드를 실행한다'는 개념을 넘어서 모델 학습에 관여하는 모든 요소들을 포함하는 개념입니다. 예를 들어 코드를 실행하기 위해서는 EC2의 컴퓨팅 인스턴스가 필요하고, 데이터를 읽고 훈련 결과를 저장하기 위해서는 S3 버킷을 활용해야 하며, 자신의 도커 이미지를 사용하기 위해서는 ECR 서비스가 필요합니다. 즉 훈련 작업을 시작하기 위해서는 사용자가 이러한 요소들을 알맞게 정의해주어야 합니다.
Estimator
가령 세이지메이커 스튜디오에서 tain.py 라는 텐서플로 훈련 스크립트를 작성했다고 가정해봅시다. 하지만 이 파일만으로는 훈련 작업을 실행할 수 없습니다. 파이썬 스크립트를 세이지메이커 훈련 작업으로 실행시키기 위해서는 에스티메이터2 객체가 필요합니다. 사실 에스티메이터라는 이름에는 오해의 소지가 있는 것 같아요 😯 저 역시 에스티메이터라는 이름 때문에 이 객체의 역할에 대해서 혼동이 있었는데, 에스티메이터는 데이터를 학습하고 추론하는 머신러닝 모델이 아니고, 오직 훈련 작업에 필요한 요소들을 정의하여 작업을 실행하는 역할만을 담당합니다.
아래 코드는 세이지메이커 스튜디오에서 훈련 작업을 시작하는 예시입니다. 에스티메이터 객체를 불러와서 소스코드, 하이퍼파라미터, 컴퓨팅 인스턴스3 등을 정의하였습니다. 이후 학습 데이터와 훈련 작업의 이름 등을 지정해서 fit 메소드를 호출하면 훈련 작업이 시작됩니다. 훈련 작업 준비가 끝나고 Training in progress.. 메시지가 출력되었다면 세이지메이커 스튜디오의 커널을 유지하지 않아도 학습이 진행됩니다. 이후 리소스 사용, 로그 출력 등 훈련 작업의 진행상황은 AWS CloudWatch에서 모니터할 수 있습니다. 훈련 인스턴스와 도커 이미지4, requirements 등 훈련 환경을 유연하게 구성할 수 있다는 점은 분명 매력적인 것 같네요😄
하지만 환경을 유연하게 변경할 수 있다는 사실은 곧 훈련 시작시 약간의 딜레이를 감수해야 한다는 것을 의미합니다. 훈련 작업을 시작하면 컴퓨팅 인스턴스를 할당받고 훈련 환경을 구성하기까지 약 5분 이내의 시간이 소요되는데, 개인적으로는 이렇게 딜레이되는 시간이 조금 아쉬웠습니다 ☹ 여기에 파일 모드 인풋을 사용하면 데이터를 다운로드하는 시간까지 포함하면 훈련 작업을 시작하기까지 꽤 오랜 시간이 걸립니다(데이터 인풋에 대해서는 뒤에서 좀 더 자세히 다루겠습니다).
훈련이 종료되면 결과물을 지정된 버킷에 저장합니다. 하이퍼파라미터와 inputs 부분은 뒤에서 다시 나올 내용이므로 눈여겨봐주세요! 하이퍼파라미터와 입력 데이터는 모두 딕셔너리로 정의하였고, 입력 데이터의 경우에는 훈련 데이터와 검증 데이터로 채널을 나누어 {channel_name: S3_path} 의 형태로 정의하였습니다. 채널 이름은 사용자가 원하는대로 정해주면 됩니다.
Training scripts
이제 훈련 작업에 사용하는 코드를 어떻게 작성해야하는지 구체적으로 알아보겠습니다. 사실 일반적인 코드와 크게 다른 점은 없지만, 몇 가지 신경써야 할 점이 있습니다. 이 글에서는 하이퍼파라미터 전달, 훈련 컨테이너 구조, 데이터 입력, 결과물 출력에 대해서 다뤄보겠습니다. 다음은 예시 스크립트의 전체 내용입니다. 간단한 MNIST 분류 모델이고, 데이터는 tfrecord 파일입니다.
train.py
datasets.py
하이퍼파라미터
위에서 에스티메이터에 하이퍼파라미터를 딕셔너리로 전달했던 것을 기억하시나요? 하이퍼파라미터는 훈련 작업이 시작될 때 entry_point 스크립트에 커맨드라인 인자로 전달됩니다. 따라서 아래 코드처럼 argparse 라이브러리로 파싱해서 사용할 수 있습니다. 혹은 SM_HP_{hyperparameter_name} 과 같은 이름의 환경변수를 통해서도 하이퍼파라미터에 접근할 수 있으므로 이를 형변환해서 사용하는 것도 가능합니다.
훈련 컨테이너 구조
/opt/ml
├── input
│ ├── config
│ │ ├── hyperparameters.json
│ │ └── resourceConfig.json
│ └── data
│ └── <channel_name>
│ └── <input data>
├── model
│
├── code
│
├── output
│
└── failure세이지메이커의 모든 훈련 작업은 도커 컨테이너에서 실행됩니다. 훈련 작업이 시작되면 세이지메이커는 컨테이너의 /opt/ml 디렉토리 아래에 위와 같은 파일 폴더 구조를 생성하며, 각 디렉토리는 고유한 역할을 가집니다. 데이터 입력/결과물 출력과도 밀접하게 관계된 내용이니 눈여겨봐주세요! 주요 디렉토리의 역할을 간단히 정리하면 다음과 같습니다. 사실 세이지메이커 컨테이너는 이미 필요한 경로들을 환경변수로 가지고 있기 때문에 경로를 일일이 하드코딩할 필요는 없습니다5.
code: 에스티메이터에 정의된 소스 디렉토리가 마운트됩니다. 소스 디렉토리에requirements.txt파일이 포함되어있으면pip install -r커맨드를 통해서 자동으로 지정된 패키지들을 설치합니다.input: 에스티메이터의hyperparameters와fit메소드의inputs파라미터에 전달된 데이터들이 마운트됩니다.model: 훈련된 모델을 저장하는 디렉토리입니다. 훈련이 종료되면 세이지메이커는 해당 디렉토리를 압축하여 S3 버킷에 업로드합니다.output: 훈련 중 출력되는 데이터들을 저장하는 디렉토리입니다. 훈련이 종료되면 세이지메이커는output/data/디렉토리를 압축하여 S3 버킷에 업로드합니다.
데이터 입력
훈련 작업 코드에서 데이터를 읽는 방법은 크게 두 가지로 분류할 수 있습니다.
- S3 버킷 경로로 직접 읽기
- S3 버킷의 데이터를 훈련 컨테이너
input으로 전달해서 읽기
첫번째 방식은 데이터가 저장된 S3 경로를 그대로 사용하면 되기 때문에 간편하고, 데이터를 인스턴스에 다운로드하는 과정이 없기 때문에 훈련 작업 시작이 걸리는 시간이 상대적으로 짧아집니다. 하지만 이 방법이 항상 가능한 것은 아니지만, 판다스나 텐서플로 등 일부 라이브러리에서는 이러한 기능을 지원하고 있습니다.
예시에서 사용한 것은 두번째 방식, 즉 훈련 작업에 명시적으로 인풋을 전달하는 방식입니다. {channel_name:S3_path} 형태의 딕셔너리로 전달한 인풋은 훈련 컨테이너의 /opt/ml/input/data/<channel_name>/<input_data> 경로에 각각 마운트됩니다. 물론 이 경로를 직접 하드코딩할 필요는 없고, 컨테이너의 환경변수를 활용하면 됩니다. 각각의 입력 채널은 SM_CHANNEL_{channel_name} 과 같은 환경변수를 통해 접근할 수 있습니다. 예시 코드에서는 디렉토리로부터 데이터셋을 만들어내는 함수를 만들어 사용했습니다.
사실 두번째 방식은 다시 파일 모드와 파이프 모드로 구분할 수 있으며, 에스티메이터에 인풋을 전달하면 기본적으로는 File 모드가 사용됩니다. 파이프 모드 인풋을 사용하려면 에스티메이터에 input_mode='Pipe' 로 설정해주면 됩니다.
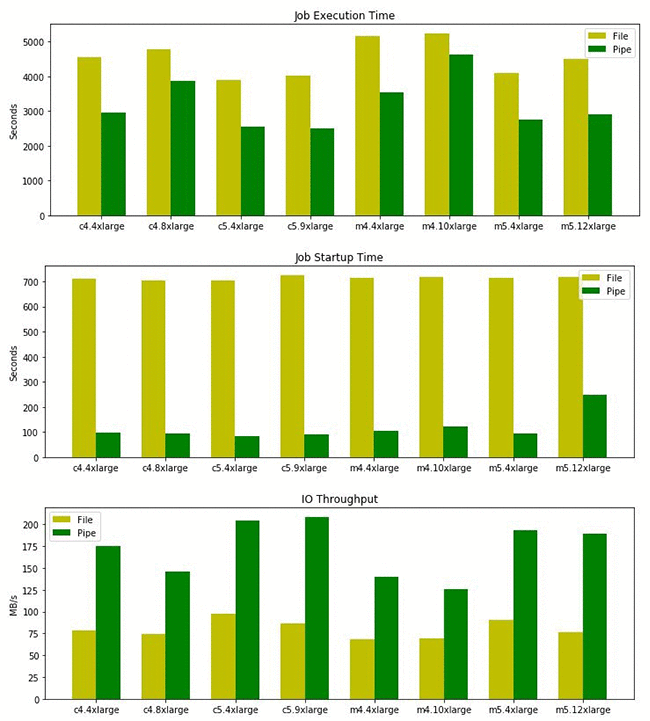
File 모드는 훈련 작업을 시작하기 전에 할당받은 인스턴스에 데이터를 전부 다운로드 받습니다. 즉 인스턴스에 충분한 디스크 볼륨이 필요하고, 데이터가 전부 다운로드된 이후에 훈련 작업이 시작됩니다. 반면 Pipe 모드는 별도의 디스크 I/O 없이 S3 버킷의 데이터를 훈련 인스턴스로 직접 스트리밍합니다. 파이프 모드는 다운로드 과정이 없기 때문에 훈련 시작 시간이 훨씬 단축되고, 디스크와 무관하게 대용량의 데이터를 처리할 수 있다는 장점이 있습니다. 아래 그림은 AWS에서 측정한 File 모드와 Pipe 모드의 성능인데 한눈에 보아도 큰 차이가 있는 것 같네요 😲 텐서플로 유저라면 세이지메이커 익스텐션의 PipeModeDataset 클래스를 함께 활용할 수 있습니다.
결과물 출력
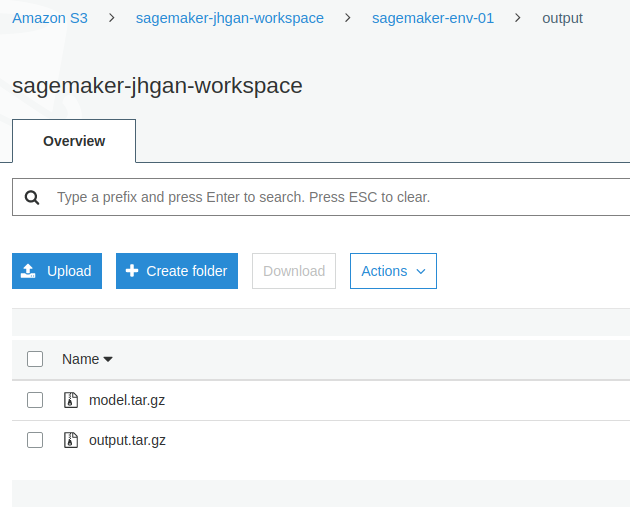
세이지메이커로부터 훈련 결과물을 제대로 돌려받기 위해서는 위에서 설명한 디렉토리 각각의 역할을 존중해주어야 합니다. 즉 학습이 완료된 최종 모델은 /opt/ml/model 에, 기타 출력물들은 /opt/ml/output/data/ 디렉토리에 저장해야 합니다. 이 경로들 역시 환경변수를 통해 접근 가능하므로 하드코딩할 필요는 없습니다. 규칙을 잘 지켰다면 모델과 기타 출력은 각각 model.tar.gz, output.tar.gz 로 압축되어 S3 버킷에 업로드됩니다.
Wrap Up
Pros & Cons
제가 느낀 세이지메이커의 가장 큰 장점은 훈련 작업의 유연성인 것 같습니다. 세이지메이커의 작업 흐름을 이해하고 있다면, 훈련 환경을 구축하는 작업이 상대적으로 간단해집니다. 프레임워크와 파이썬 버전을 정하고, 인스턴스를 정하고, requirements.txt 파일을 작성하면 간단하게 학습 환경을 구축할 수 있습니다(물론 도커 이미지를 아예 새로 만들려고 한다면 조금 번거로울 수는 있습니다). 아쉽게도 제가 직접 경험한 장점은 이것뿐입니다 😅 사실 세이지메이커에는 pre-built 머신러닝 모델, 실험 작업, 모델 배포 등 좋은 기능들이 많습니다! 다만 제 능력이 모자라서 모두 사용해보지 못했고, 구체적으로 어떤 점이 좋은지를 말씀드리지 못하겠네요.
하지만 단점은 좀 더 많이 준비되어있습니다 😈 첫째로는 훈련 작업 시작이 느리다는 점입니다. 훈련 환경을 그때그때 구축하기 때문에 유연하지만, 여기에 소요되는 시간 역시 무시할 수 없습니다. 둘째로는 훈련 작업에 다양한 서비스들이 엮여있어 뉴비에게 상당히 혼란스럽다는 점입니다. 세이지메이커를 사용하기 위해서는 세이지메이커뿐 아니라 AWS의 생태계 일반에 어느 정도 적응이 필요해 보입니다. 셋째로는 주피터 랩에 기반하기 때문에 코드 편집 기능이 상대적으로 약하다는 점입니다. 주피터를 좋아하기는 하지만, 코드 편집만 놓고 보면 메모장보다 약간 나은 수준이라고 생각합니다.
마지막의 마지막으로!
사실 이 마무리 멘트를 쓰는 시점이 프로메디우스 인턴 사원으로서의 마지막 날입니다. 돌아보니 ML 팀의 인턴사원으로 들어왔지만 ML 논문과 코드를 들여다본 시간만큼 세이지메이커를 다루는데도 많은 시간을 들였던 것 같아요. 이렇게 정리해놓고 보니 기본적은 훈련 작업은 그렇게 어려운 내용이 아닌 듯 한데 AWS, 도커 등등 처음 접하는 것들이 많아서 그런지 꽤 많이 헤맸네요. 그래도 같이 입사한 동주 인턴과 여러 직원분들이 도와주신 덕에 처음 접하는 환경에서도 무사히 프로젝트를 진행할 수 있었습니다! 이번 인턴십이 아니었다면 개인적으로 AWS를 사용해볼 일은 없었을 것이고, 비싼 인스턴스를 펑펑 사용해볼 일을 더욱 없었을 것이고, 언제나 저에게 큰 도움이 되어주신 프로메디우스 직원분들을 만날 일은 더더욱 없었을 거에요. 여러모로 즐겁고 잊지 못할 경험이었습니다! 모두들 안녕!
참고
Footnotes
- 세이지메이커 스튜디오의 인스턴스 할당량 증가 요청 메뉴는
AWS Support Center > Service limit increase에서 찾아볼 수가 없습니다. 이 문제 때문에 많이 헤맸는데, 문의 결과 지금은 Technical support에 직접 요청하는 것이 가장 빠른 방법이라고 합니다 ↩ - 자세한 내용은
EstimatorBase,TensorFlow문서를 참고하세요 ↩ AWS Support Center > Service limit increase메뉴에서 훈련용 인스턴스 할당량 증가를 요청할 수 있습니다 ↩- 자신의 도커 이미지를 사용하려면 Get Started: Build Your Custom Training Container with Amazon SageMaker
를, AWS 딥러닝 컨테이너에 대해서는 AWS Deep Learning Containers
를 참조하세요 ↩ - 컨테이너에의 환경변수에 자세한 정보는 sagemaker-training-toolkit에서 확인하실 수 있습니다 ↩