[GAN 시리즈][DCLGAN] Dual Contrastive Learning for Unsupervised Image-to-Image Translation - 1편

![[GAN 시리즈][DCLGAN] Dual Contrastive Learning for Unsupervised Image-to-Image Translation - 1편](/content/images/size/w2000/2021/07/DCLGAN-figure-1.png)
Abstract
Unsupervised image-to-image translation 개념
Unsupervised image-to-image translation tasks는 unpaired train data에서 source domain X와 target domain Y 간의 매핑(mapping)을 찾는걸 목표로 하는 task 입니다.
CUT(Contrastive Learning for unpaired image-to-image Translation)
Contrastive Learning for unpaired image-to-image Translation은 두개의 도메인 (X, Y) 모두에 대해 하나의 Encoder만 사용하여 입력 및 출력 패치(patch)의 mutual information을 최대화 하여 Unsupervised image-to-image translation을 모델링 하는 SOTA 결과를 제공합니다.
🗣 하지만 데이터 도메인에 따라 mode collapse가 발생한다는 문제점이 존재합니다. 이를 해결하기 위해 DCLGAN의 변형인 SimDCL도 소개하고 있습니다.
제안한 방법
본 논문에서는 unpaired data간의 효율적인 매핑을 하기 위해 contrastive learning, dual learning setting에 기반한 새로운 학습 방법을 제안합니다.
mode collapse 문제 해결
cycle consistency loss의 문제점들을 해결 하기 위해 self-supervised representation learning 분야에서 multiple views of the data간의 contrastive learning을 이용한 CUT이 SOTA를 찍었지만 mode collapse 문제가 발생합니다.
이 논문에서 제안한 방법으로 mode collapse 문제를 효율적으로 해결합니다.
📌 CUT vs DCLGAN(제안한 방법)
- CUT: 1개의 Encoder 사용, 데이터에 따라 mode collapse 문제 발생.
- DCLGAN: 2개의 Encoder 사용, mode collapse 문제를 효율적으로 해결.
결론
image-to-image translation tasks에서 extensive ablation study을 통해 다른 네트워크들에 비해 본 논문에서 제안한 접근 방식이 효과적이라는 것을 본 논문에서 입증합니다.
끝으로, unsupervised learning과 supervised learning 방법 사이의 격차를 효율적으로 줄일 수 있음을 보여줍니다.
Introduction
image-to-image translation task는 이미지를 한 도메인에서 다른 도메인으로 변환하는 것을 목표로 합니다. 가장 일반적으로 사용하고 있는 방법은 GAN을 기반으로 하는 방법입니다.
GAN이 발전하게 된 큰 이유중 하나는 adversarial loss 입니다. 하지만 adversarial loss를 unpaired unsupervised image-to-image translation에 사용하여 발생되는 문제점은 adversarial loss가 underconstrained 하다는 점 입니다.
🗣 adversarial loss가 underconstrained 하다면?
💡 두 도메인 사이에 여러개의 매핑이 존재하게 되어 네트워크 학습이 불안정하게 됩니다.
그래서 위와 같은 문제를 해결하기 위해 unpaired unsupervised image-to-image translation에서는 cycle consistency을 사용하여 문제점을 해결했습니다.
cycle consistency
cycle consistency loss는 (그림 1)처럼 target Domain ➡️ source Domain 으로 역방향 매핑을 학습할 때 사용하는 loss 입니다.
🗣역방양 매핑을 학습한다는 의미는?
💡 입력된 이미지와 재구성된 이미지가 얼마나 동일하게 만들어 지는지를 학습하는 의미이며 cycle consistency loss가 그 차이를 측정하며 학습을 하게 됩니다.
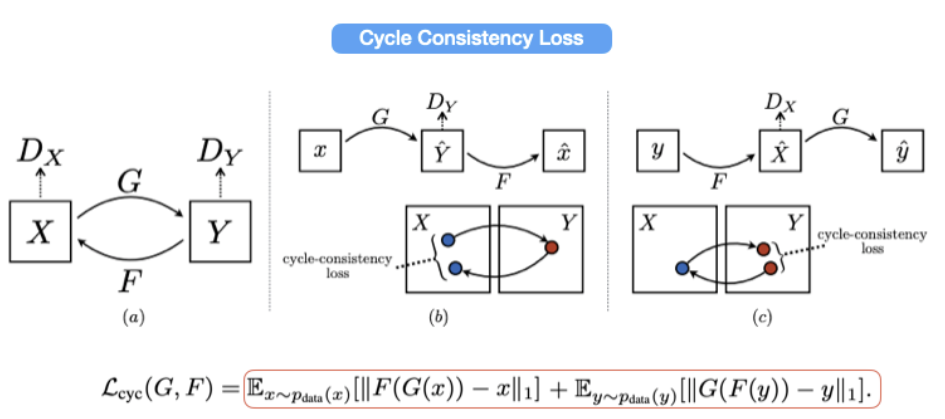
하지만 cycle consistency을 사용할 때 약간의 가정과 제약이 있습니다.
📌 cycle consistency의 가정
- 변환된 이미지는 target domain과 유사한 texture information을 가지므로 geometry 변경이 불가하다는 것을 가정으로 두고 cycle consistency를 사용합니다.
- 두 도메인 (X, Y) 간의 관계가 bijection 되도록 즉, 1:1 대응이 되도록 합니다.
📌 cycle consistency의 제약
- 그로 인해 정확도 손실로 인해 재구성 과정이 제한되므로
재구성 이미지의 diversity가 감소하게 됩니다.
그래서 이러한 제약을 해결하기 위해 Contrastive Learning을 이용한 연구가 등장을 하게 되었습니다.
Contrastive Learning을 이용한 Image-to-Image Translation
cycle consistency loss는 재구성 이미지의 diversity가 감소하게 되는 등의 제약들이 발견되었습니다. 따라서 이를 해결하기 위해 self-supervised representation learning 분야에서 multiple views of the data 간의 contrastive learning 방법이 이루어 졌습니다. 이 방법이 기존 cycle consistency loss을 사용한 방법의 제약을 효율적으로 해소함을 보여줌과 동시에 SOTA를 달성하게 되었습니다.
가장 최근에 나온 논문 중 대표적인 논문으로 CUT(Contrastive Learning for Unpaired Image-to-Image Translation)이 있습니다. CUT는 unpaired image-to-image translation taks에서 contrastive learning 방식이 효율적이라는 것을 보여주었으며, patch-based multi-layer PatchNCE loss을 사용하여 unpaired image-to-image translation을 위한 Contrastive Learning을 도입하여 입력 및 출력 이미지의 패치간의 mutual information을 최대화 하는 방향으로 학습이 이루어지게 됩니다.
하지만 SOTA를 찍은 CUT도 문제점이 보였습니다. 그 문제점은 바로 아이디어는 좋았지만 두 도메인 (X, Y) 사이의 domain gap을 효율적으로 포착하지 못하여 충분히 성능을 끌어올리지 못하고 있다는 점 입니다.
🗣 그럼, 왜 성능을 충분히 끌어 올리지 못했을까요?
💡 그 이유는 바로 CUT에서 사용한 아키텍처의 특정 부분의 디자인을 잘못 선택해서 성능이 떨어지게 되었습니다.
domain gap을 효율적으로 포착하기 위해서는 도메인 수 만큼 임베딩이 사용되어야 합니다. 하지만 CUT는 하나의 임베딩이 사용되어 성능을 제한하고 있다고 본 논문에서 주장을 하고 있습니다.
그래서 본 논문에서는 cycle-consistency의 제약을 피하고, domain gap을 효율적으로 포착할 수 있도록 한개 이상의 임베딩을 사용하고, contrastive learning 방법을 더욱 활용한 DCLGAN을 제안합니다.
DCLGAN
📌 목표
DCLGAN의 목표는 별도의 임베딩을 사용하여 입력 및 출력 이미지 패치의 상관관계를 학습하여 mutual information을 극대화 하는 것을 목표로 합니다.
📌 학습 방법
DCLGAN은 CUT의 성능을 제한시킨 디자인인 1개의 임베딩을 사용하는 점을 개선시켜 서로 다른 도메인에 서로 다른 Encoder 및 projection heads를 사용함으로써 두 도메인 간의 접점이 되는 부분을 극대화 시키기 위한 1개 이상의 임베딩을 학습합니다.
📌 발견한점
- CUT과 달리 DCLGAN의 학습 방법은 dual learning 방식 입니다. 이 방식이 오히려 학습을 안정화 시키는데 도움이 된다고 합니다.
- 또한 CUT에서 사용한 PatchNCE loss에서 RGB pixel을 제거하는 것이 학습하는대에 있어 도움이 될 수 있음을 발견했습니다.
- geometrical structure에 대한 제약이 없는 경우에는 cycle-consistency가 불필요 하다는 점도 발견했습니다.
- DCLGAN은 데이터 도메인에 따라 mode collapse가 발생될 수 있지만 그 변형인 SimDCL은 mode collapse를 방지하는데 효과적인 점을 발견했습니다.
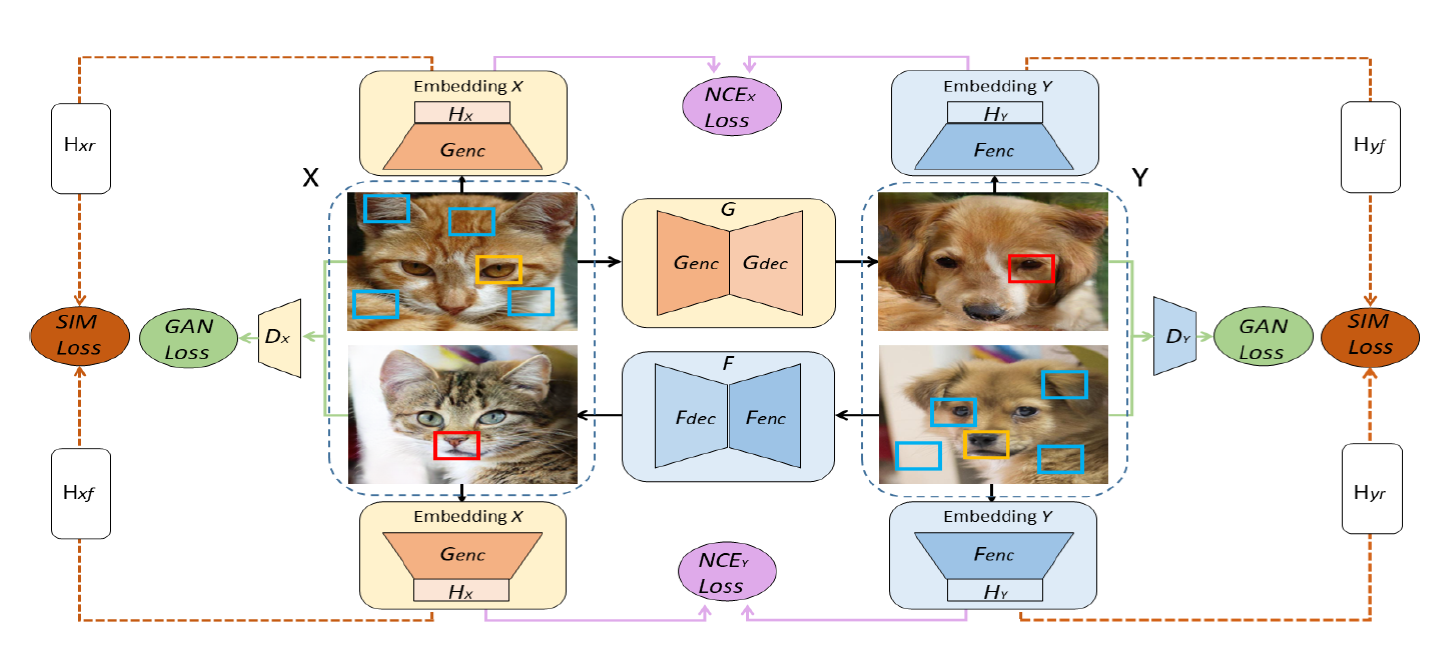
정리
본 눈문은 CycleGAN과 CUT의 한계를 극복할 수 있는 새로움 프레임 워크와 변형 네트워크를 제시하고 있습니다.
🗣 CycleGAN
- cycle consistency으로 발생하는 단점.
🗣 CUT
- contrastive learning의 효율성을 보여주었지만 한개의 임베딩을 사용해서 domain gap을 효율적으로 포착하지 못할 수 있다는 한계점.
또한 여러가지 다양한 실험을 통해 SOTA에 비해 본 논문에서 제안한 방식이 훨씬 효과적이라는 점을 입증하게 되었으며, self-supervised learning 분야에서 contrastive learning 방법이 그랬던것 처럼 unsupervised and supervised learning 방법 사이의 격차를 성공적으로 좁힐 수 있다는 점을 보여주고 있습니다.
Related Work
Supervised methods
📌 관련 논문: Pix2Pix, Pix2PixHD, SPADE
Pix2Pix
general methods만 사용하여 여러개의 image-to-image translation tasks을 지원하는 작업에 구애받지 않는 image translation을 처음 수행한 논문 입니다.
Pix2PixHD
기존 Pix2Pix 논문에서 확장된 방법으로, 고해상도 이미지를 합성할 수 있는 방법 입니다.
SPADE
생성된 이미지의 품질을 더욱 향상 시키기 위해 spatially-adaptive normalization layer을 도입한 논문입니다.
😱 단점: supervised 접근 방법은 학습을 위해 paired data가 필요합니다.
Unsupervised methods
📌 관련 논문: MUNIT, DRIT, StarGAN
비지도 학습 방법은 주로 shared latent space, cycle-consistency assumption을 가정을 두고 있습니다.
MUNIT
latent space을 style code & content code로 분리하여 domain-specific features를 분리하는 특징이 있는 논문 입니다.
DRIT
domain-specific attribute space and shared information을 포착하는 content space을 포함한 두 space에서 이미지 임베딩을 하는 논문 입니다.
StarGAN
대표적인 multi domain image-to-image translation 으로, unified model architecture을 사용하여 여러 도메인에서 이미지를 translation 하는 논문 입니다.
Break the cycle
📌 관련 논문: CycleGAN, CouncilGAN, DistanceGAN, GCGAN
CycleGAN
대표적인 unpaired data image-to-image translation으로 cycle-consistency loss을 사용하여 adversairal loss의 문제인 mode collapse 단점을 극복하기 위한 네트워크로, 입력 이미지를 target domain으로 변환하고 입력 및 생성된 이미지의 정확도를 유지하며 두개의 매핑을 동시에 학습하는 네트워크 입니다.
하지만 cycle-consistency의 문제를 완화하기 위해 break the cycle을 시도하고 있으며 대표적인 네트워크가 CUT 입니다.
CouncilGAN
council loss와 함께 두개 이상의 Generator, Discriminator을 사용합니다.
⭐️ 본 논문에서는 CycleGAN, CUT의 장점을 모두 활용합니다. 특히 mutual information maximization을 통해 cycleGAN 아키텍처를 기반으로 한 양방향 unsupervised image-to-image translation이 가능하도록 합니다.