[F-AnoGAN] Fast Unsupervised Anomaly Detection with GAN

![[F-AnoGAN] Fast Unsupervised Anomaly Detection with GAN](/content/images/size/w2000/2020/10/f-AnoGAN_figure1-1.png)
- GAN을 사용한 최초 Anomaly Detection 방법인 AnoGAN의 후속 모델로 Encoder 모델을 사용하여 더 빠르게 \( G(x)\)와 \( x\)를 matching 시켜 Anomaly Detection 하는 방법입니다.
- Paper 원문: f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks
- f-AnoGAN tutorial code(Pytorch): https://github.com/mulkong/f-AnoGAN_with_Pytorch
1. Abstract
[문제점]
정확한 annotation은 시간이 많이 들기 때문에 전문가(방사선사, 의사 등)가 clinical imaging(임상 영상)을 직접 annotation을 표시한 데이터를 얻는 것은 어렵다. 또한 모든 병변에 대해 annotation이 표시되지 않을 수 있으며 annotation에 대해서 정확하게 이 병변이 어떤 병변인지 설명 되어있지 않은 경우도 있다.
[Supervised Learning의 장단점]
전문가로부터 분류된 training data를 받아 Supervised Learning 방식으로 모델을 학습 시키면 좋은 성능을 얻는 반면, annotation이 표시된 병변으로만 제한이 되는게 단점이다.
[Unsupervised Learning으로 접근한 f-AnoGAN을 제안]
본 논문에서는 biomarker candidates를 할 수 있는 anomalous images 및 image segments를 식별할 수 있는 GAN 기반 Unsupervised Learning 접근법으로 해결하는 f-AnoGAN(fast AnoGAN)을 제안한다.
[Fast mapping technique of new data]
Normal data로 Generator model을 학습 시키고 GAN latent space에서 query data \( X\)(병변 유무를 확인하고 싶은 테스트 영상)의 fast mapping technique를 제안하고 평가한다. latent space mapping 방법은 Encoder를 기반으로 이루어지며 Discriminator feature residual error 및 image reconstruction error \( G(z)\)를 포함하는 훈련된 모델을 기반으로 anomaly detection이 진행된다.
Optical Coherence Tomography(OCT) 촬영 데이터를 사용한 딥러닝 학습 관련 실험은 본 논문에서 제안한 방법과 대체 접근법(AnoGAN, BiGAN 등)과 비교하며 실험한다. 본 논문에서 제안한 f-AnoGAN 방법이 anomaly detection의 정확도를 높인다는 포괄적인 경험적 증거를 제공한다. 또한 두 명의 망막 전문가를 대상으로 한 시각적 테스트 결과 생성된 이미지 \( G(z)\)가 실제 OCT 이미지와 구별이 잘 안되는 것으로 나타났다.
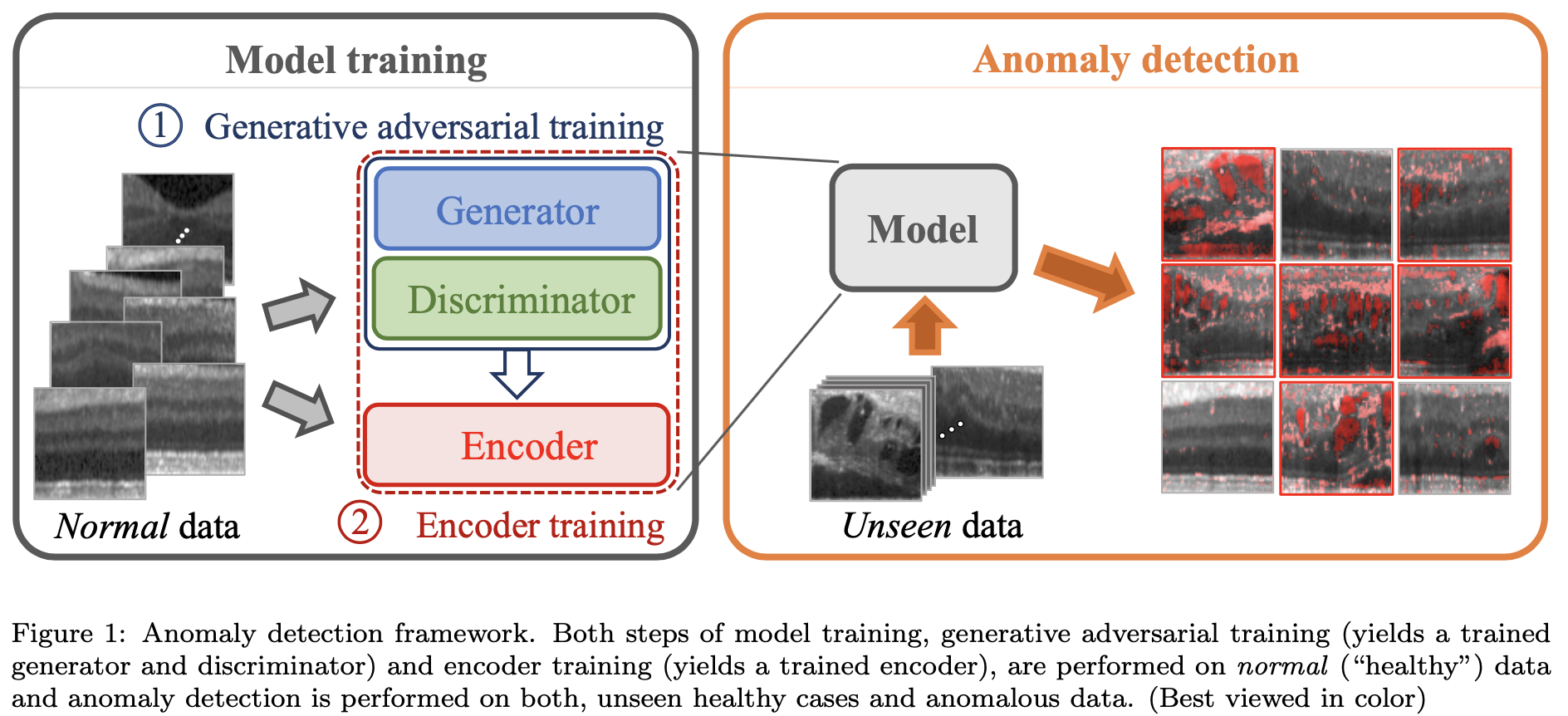
2. Fast GAN based anomaly detection
본 논문에서 제안한 Anomaly Detection 순서는 크게 두가지로 이루어 집니다.
- normal image에 대한 GAN 학습
- 잘 학습된 GAN을 기반으로 GAN 학습때 사용한 normal image를 그대로 사용하여 Encoder 학습.
f-AnoGAN의 핵심은 image를 latent space에 mapping하는 방법으로 Encoder 모델을 사용한 것이 핵심입니다. 비슷한 방법인 AnoGAN과 비교를 해보면 확실한 차이점을 확인할 수 있습니다.
AnoGAN
AnoGAN의 목표는 query image \( X\)가 주어지면 query image \( X\)와 가장 유사하고 Manifold \( X\)에 위치하는 \( G(z)\)의 latent space를 찾는 것 입니다. 이 과정에서 \( G(z)\)의 Probability density function에 의존하게 됩니다.
mapping된 latent space의 세부적인 과정은 다음과 같습니다.
- random하게 \( z_n\)을 뽑아 \( G(z_n)\)을 얻는다.
- query image \( X\)와 유사한 \( G(z)\)를 찾기 위해 latent space 안에서 최적의 \( z\)를 찾기 위해 residual loss + discrimination loss를 기반으로 backpropagation을 통해 찾는다. (oct 기준 500 iteration)
- 최종적으로 residual loss 수식을 그대로 사용하여 anomaly score를 계산한다. (anomaly score 구하는 방법은 f-AnoGAN에서도 동일하게 적용 됩니다.)
위에서 설명드린 방법은 학습 이미지 크기가 작으면 효율적이고 나름 빠르게 진행이 되지만 이미지 크기가 크면 클수록 그만큼 많은 정보들을 고려해야 하므로 random하게 iteration하며 학습하는 AnoGAN 방법은 mapping이 제대로 안되는 경우가 발생할 수 있습니다.
f-AnoGAN
f-AnoGAN은 이런 문제를 해결하고자 AutoEncoder에서 아이디어를 얻었다고 할 수 있습니다. AutoEncoder는 입력된 정보들을 잘 설명할 수 있는 latent vector로 차원을 압축 시켰다가 Decoder를 통해 복원하는 간단한 모델입니다. 이 과정에서 사용된 Encoder 모델을 f-AnoGAN에서는 image를 latent space에 mapping하는 모델로 사용된 것 입니다. 이렇게 학습 데이터를 latent space에 mapping 시켜주는 과정은 identity transformation(항등변환) 해주는 과정이라고 할 수 있으며 입력 이미지가 들어가면 그대로 Decoder를 통해 동일한 이미지로 복원하는 identity mapping이라고도 할 수 있습니다.
2-1. Learning a fast mapping from images to encodings in the latent space
GAN 학습은 latent space \(Z \rightarrow \) Manifold \( X\)로 mapping되는 \( G(z) = z \rightarrow x\)를 생성하지만 Anomaly Detection에서 피룡한 Manifold \( X \rightarrow\) latent space \( Z\)로 inverse mapping은 불가능 합니다. (이 개념은 AnoGAN 논문에서도 언급된 개념입니다.)
inverse mapping이 안되는 문제점을 해결하고자 AnoGAN에서는 위에서 언급한 방법으로 latent space에 mapping을 해주었지만 f-AnoGAN에서는 Deep Encoder Network를 사용하여 \( E(x) = x \rightarrow z\) 즉, inverse mapping이 가능하도록 학습을 진행합니다. 이 방법을 사용하여 f-AnoGAN제안한 방법은 크게 2가지 방법입니다.
- \( z \rightarrow image \rightarrow z\)
- \( image \rightarrow z \rightarrow image\)
이 두가지 방법 모두 (그림 2)처럼 image에서 latent space \( Z\)로 mapping 하는 방법입니다.
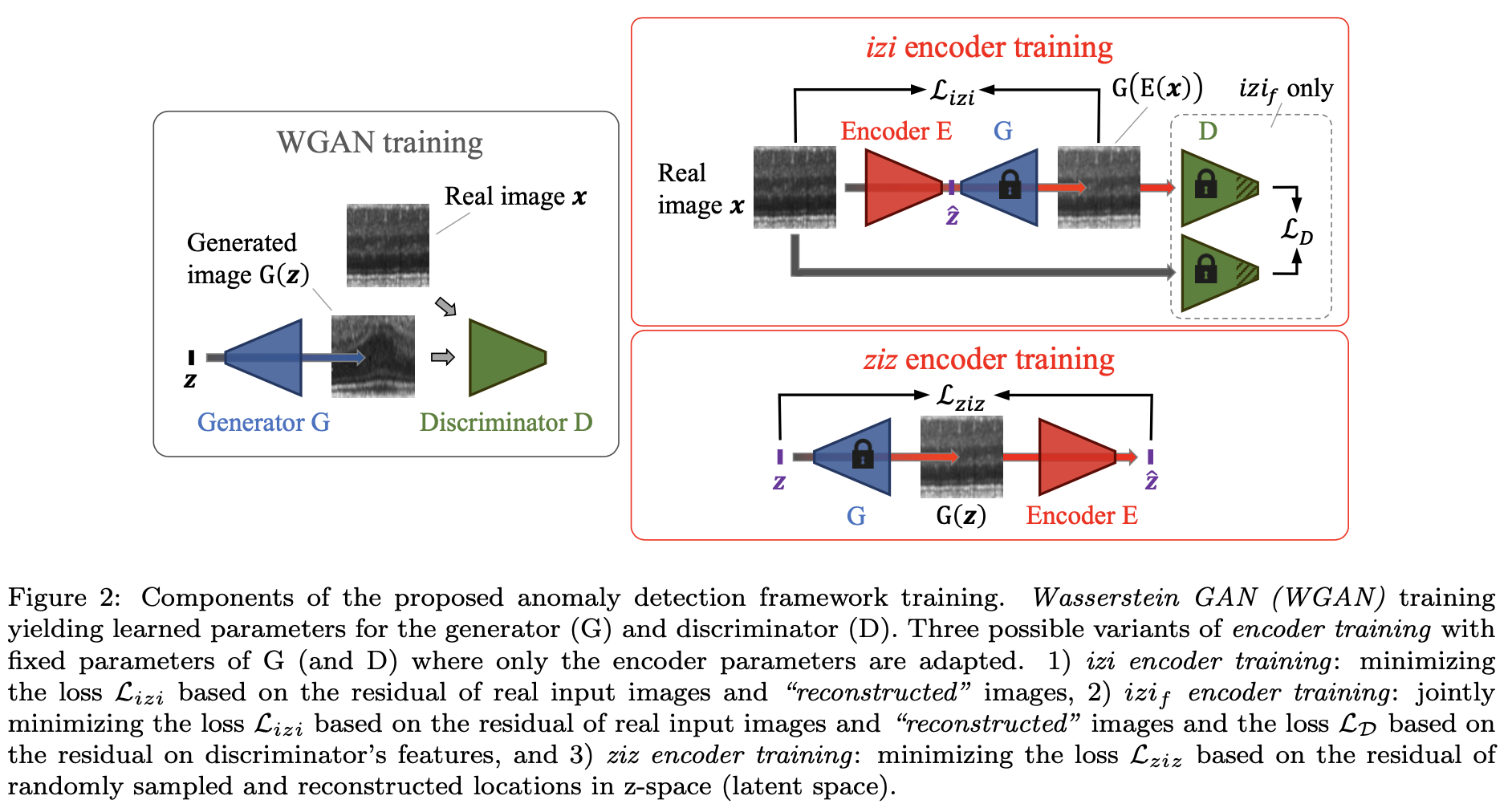
2-2-1. Training the encoder with generated images: \( ziz\) architecture
학습중 latent space \( Z\)로 부터 random sampling된 latent vector \( z\)는 더이상 weight가 update 안되는 fixed weight \( G\)를 통해 image space에 mapping 되고 Encoder는 이를 다시 latent space \( Z\)에 mapping 하도록 학습 합니다. 따라서 \( ziz\) architecture의 경우 GAN 학습할 때 사용했던 normal image가 필요 없습니다.
\( ziz\) architecture로 학습할 때 사용되는 loss는 \( z\)와 \( E(G(z))\)의 MSE를 최소화 하는 방법으로 학습이 진행됩니다.
$$ L_{ziz}(z) = \cfrac{1}{d}||z - E(G(z))||^{2} $$
\( ziz\) architecture 방법은 학습할 때 생성된 이미지만 잘 mapping될 뿐 query image \( X\)가 들어오면 제대로 mapping을 못하게 된다는 단점이 있어 f-AnoGAN 논문에서는 해당 방법으로 학습을 진행 안합니다.
2-2-2. Training the encoder with real images: \( izi\) architecture
학습하는 동안 real image에서 latent space \( Z\)로 encoding되어 mapping하는 과정은 Encoder model로 이루어 집니다. 이런 과정을 통해서 query image \( X\)가 들어오면 AnoGAN에서 사용한 iteration을 시켜주는 방법 없이 빠르게 \( X\)와 구조적으로 일치한 \( G(E(x))\)를 생성할 수 있게 됩니다.
\( izi\) architecture로 학습할 때 사용되는 Losssms \( x\)와 \( E(G(x))\)의 MSE를 최소화 하는 방법으로 학습이 진행됩니다.
$$ L_{izi}(x) = \cfrac{1}{n}||x - G(E(x))||^{2} $$
\( izi\) architecture는 GAN을 학습할 때 사용한 학습 데이터를 이용해서 학습이 진행 됩니다.
\( izi\) architecture의 단점
\( X\)가 latent space \( Z\)에서 정확하게 어디에 위치하는지 \( ziz\) architecture는 \( G(z)\)를 바로 latent space에 mapping 시켜서 알 수 있었지만 \( izi\) architecture는 알 수 없습니다. 따라서 image space로 다시 mapping 하고 \( image-to-image\) residual loss를 계산하여 \( image-to-z\) mapping의 정확도를 간접적으로 측정할 수 밖에 없습니다.
이런 방법으로 진행하면 query image로 normal image가 들어오면 괜찮지만 abnormal image가 들어오면 residual 이 적은 이미지가 생성될 수 있습니다. 따라서 이런 문제점으로 본 논문에서는 feature space를 loss로 사용해서 mapping이 이루어질 수 있도록 \( izif\) architecture를 고안하게 되었습니다.
2-2-3. Discriminator guided \( izi\) encoder training: \( izif\) architecture
\( izi\) architecture 문제점을 해결하기 위해 Discriminator model의 중간 계층인 feature space에서 residual loss를 추가적으로 사용하여 Encoder model을 학습합니다.
$$ L_{izif}(x) = \cfrac{1}{n}\cdot||x - G(E(X))||^{2} + \cfrac{k}{n_d}\cdot||f(x) - f(G(E(x)))||^{2} $$
*nd: 중간 계층의 feature space의 dimension
*k: weight factor
수식을 보면 Discriminator feature space는 AnoGAN에서 사용된 loss와 관련이 있는것을 볼 수 있습니다. Discriminator feature는 GAN을 학습할 때 얻은 parameter들을 사용한 것 입니다. feature space를 loss로 사용하게 되면 image space와 latent space에서 잘 mapping이 되도록 약간의 guide를 제공해주는 역할을 하게 됩니다.
2-3. Detection of anomalies
GAN도 학습이 잘 되었고 Encoder도 학습이 잘 되었다면 이제 query image \( X\)를 입력으로 넣어서 anomaly score를 계산하면 됩니다. anomaly score를 계산하는 것은 image level의 anomaly detection중 query image와 reconstruction image의 deviation을 score로 나타내야 합니다.
이 score를 anomaly score라고 하며 수식은 아래와 같습니다.

수식을 보면 \( loss_{izif}\) 수식과 동일한 것을 볼 수 있습니다.
일반적으로 수식 모두 abnormal image에서 높은 anomaly score, normal image는 낮은 anomaly score가 계산됩니다. 모델은 normal image에 대해서만 학습하므로 입력 이미지와 시각적으로 유사한 이미지만 normal image의 Manifold \( X\)에 눞혀서 Encoder를 통해 재구성 됩니다.