가볍게 만나는 YOLO!
안녕하세요, 프로메디우스 인턴사원 간정현입니다. 이번 포스팅에서는 YOLO와 다크넷 프레임워크를 간단히 소개하고, 다크넷 사용 후기를 공유하려고 합니다. 부족한 글이지만 재밌게 봐주시면 감사하겠습니다!
You Only Look Once 😎
Overview
YOLO(You Only Look Once)는 빠른 추론 속도와 상당한 정확도를 자랑하는 오브젝트 디텍션 모델입니다. 오브젝트 디텍션은 객체의 위치와 크기를 예측하는 문제와 해당 객체의 클래스를 분류하는 문제로 세분화할 수 있습니다. 모델에 따라서 이 두 가지 문제를 한번에 처리하기도 하고, 두 단계로 나누어 처리하기도 합니다. YOLO는 이름에서 알 수 있듯이 하나의 네트워크에서 객체의 위치와 크기, 클래스를 동시에 예측하는 방식을 채택합니다.
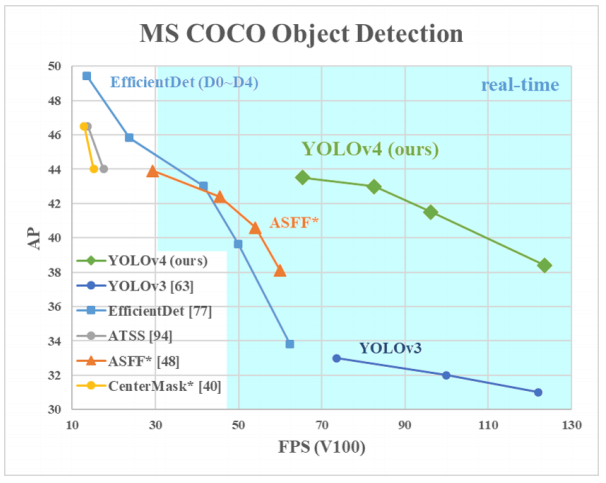
YOLO의 아이덴티티는 실시간 수준의 빠른 예측 속도를 유지하면서도 꽤 정확한 예측을 내놓는다는 점에 있습니다. 일반적으로 위치 예측과 클래스 분류를 한꺼번에 수행하는 간결한 파이프라인을 채택할 경우 예측 속도 면에서는 유리하지만 정확도 면에서는 불리합니다. YOLO 역시 정확도만 놓고 보면 가장 뛰어난 모델이라고는 할 수 없습니다. 하지만 추론 속도를 함께 고려하면 상황이 달라집니다. 위 그림처럼 실시간 수준의 추론 속도를 가진 모델들 중 YOLOv4는 압도적인 성능을 보입니다.
YOLOv1: outputs

YOLOv1을 통해서 모델의 학습 과정을 조금 살펴봅시다. 위 그림은 네트워크의 아웃풋을 나타낸 것입니다. 아웃풋이 만들어지는 과정을 보다 구체적으로 살펴보면 아래와 같습니다.
- 이미지를 S x S의 그리드로 나눕니다.
- 각 그리드 셀은 B 개의 바운딩 박스를 예측합니다.
- 각 그리드 셀은 바운딩 박스와 무관하게 C 개의 클래스 확률을 예측합니다.
- 각 바운딩 박스는 클래스와 무관하게 객체의 존재 여부(confidence), 위치(x,y), 크기(w,h)를 예측합니다
- 따라서 모델의 아웃풋은 (S, S, B x 5 + C)의 텐서가 됩니다(바운딩 박스의 갯수만을 따지면 S x S x B 가 됩니다).
- 논문에서는 S=7, B=2를 사용하였습니다. 즉 클래스가 20개인 데이터셋에 대해서 위 그림처럼 (7, 7, 30) 크기의 텐서를 출력합니다.
- 훈련 이후 실제 예측시에는 non-maximal surpression 을 적용합니다.
confidence 의 정답은 실제 바운딩 박스와 예측된 바운딩 박스의 IOU 값으로 정해집니다. 특이하게도 정답을 결정하는데 예측치가 관여하는 것입니다! 디텍션 분야를 처음 접한 입장에서는 정답을 결정하는데 예측치가 관여할 수 있다는 컨셉이 굉장히 당황스러웠고 헷갈렸습니다. 여기서는 당황하지 말고 천천히 살펴봅시다!
논문에서는 모델이 내놓는 confidence 점수를 Pr(Object) x IOU로 정의합니다. 예측된 박스 안에 객체가 존재하지 않는다면, 이상적인 모델에서는 Pr(Object)가 0이 되어 confidence 역시 0이 되어야 합니다. 반대로 예측된 박스 안에 객체가 존재한다면, 이상적인 모델에서는 Pr(Object)가 1이 되어 confidence 는 IOU와 같아져야 합니다. 이러한 성질로 인해서 연구자들은 confidence 점수와 IOU를 예측치-정답의 쌍처럼 사용할 수 있다고 판단한 것 같네요!
YOLOv1: loss

위 수식은 YOLOv1의 로스 함수입니다. 😈 무시무시하게 생겼지만 사실 자세히 뜯어보면 그렇게까지 험악한 친구는 아닙니다 😇 기본적으로 좌표, 크기, 컨피던스, 클래스 확률의 평균제곱오차를 계산한 후 모두 더하는 구조로 되어있습니다. 여기에서 로스의 모든 디테일을 리뷰할 수는 없으니 "responsible" 의 개념에 대해서만 짚고 넘어가려 합니다.
(p.2) If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
(p.3) At training time we only want one bounding box predictor to be responsible for each object. We assign one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth.
위 인용을 보면 "responsible" 이라는 개념은 그리드 셀에 대해서도, 바운딩 박스에 대해서도 쓰입니다. 하지만 로스의 관점에서 "responsible" 은 결국 바운딩 박스에 대한 개념으로 생각하면 됩니다. 즉 하나의 물체에 대한 예측을 책임지는 유일한 바운딩 박스를 결정하는 문제입니다. 수식을 보면 예측에 대해 "responsible" 하지 않은 박스의 좌표 크기 로스 텀은 0이 되는 것을 알 수 있습니다. 즉 책임이 없는 박스들에 대해서는 좌표와 크기의 로스를 면제해주자는 아이디어입니다. 천천히 따져봅시다!
먼저 그리드 셀의 단위에서는 해당 셀이 어떤 물체의 중심을 포함하는 경우 그 물체의 탐지에 대해 "responsible"하다고 합니다. 하지만 모델의 구조상 하나의 그리드 셀은 여러 개의 바운딩 박스를 예측하게 됩니다. 하나의 물체에 대해 정확히 하나의 바운딩 박스를 대응시키기 위해 바운딩 박스에 대해서도 "responsible" 의 조건을 정의해야 합니다. 바운딩 박스에 대해서는, 물체에 대해 가장 높은 IOU를 갖는 박스를 물체에 대해 "responsible" 하다고 정합니다. 정리하면, 어떤 물체의 중심을 포함하는 셀에서 예측된 바운딩 박스 중 실제 바운딩 박스와 가장 큰 IOU를 갖는 박스를 그 물체에 대해 "responsible" 하다고 말합니다.
Darknet
다크넷은 Joseph Redmon이 YOLO 학습을 위해 개발한 프레임워크입니다. 하지만 대부분의 사용자들은 YOLOv4의 저자인 Alexey Bochkovskiy의 버전을 사용하는 듯 하고, 업데이트도 포크 버전에서 더욱 활발하게 이루어지는 것 같습니다. 저 역시 포크 버전을 사용했는데, 개인적으로는 프레임워크 전반에 대한 문서와 설명이 오리지널 웹사이트보다 훨씬 상세하다고 느꼈습니다. 저뿐만 아니라 다른 분들도 다양한 이유로 오리지널 버전보다는 Alexey 버전을 선호하시는 것 같습니다!
데이터셋 제작
<object-class> <x> <y> <width> <height>
모델을 만들기 위해서는 우선 데이터가 있어야겠죠? 다크넷 학습을 위해서는 이미지와 라벨의 쌍으로 이루어진 데이터셋이 필요합니다. 저는 흉부 X-ray 사진에서 L 자 마커를 찾아내는 모델을 학습시키기 위해 사내 데이터 2,200장, 오픈 데이터 200장을 직접 레이블링했습니다. 레이블링 작업은 정말 힘들고 괴롭지만 마치고 나면 묘한 성취감이 느껴져요 😄
레이블링 작업에는 Yolo_label이라는 툴을 사용했습니다. 이 툴의 장점은 다크넷의 라벨 데이터 형식을 그대로 따르기 때문에 만들어진 데이터를 별도의 전처리 없이 즉시 다크넷에 주입할 수 있다는 것입니다. 또한 드래그 & 드롭 방식이 아닌 클릭 & 클릭 방식을 사용해서 손목의 부담도 확실히 덜합니다. 사실 예전에도 3개월 정도 자율주행을 위한 데이터를 레이블링해본 적이 있는데, 그 당시 사용한 툴과는 비교도 되지 않을만큼 편했습니다. 직접 다크넷에 들어갈 데이터를 제작해야하는 상황이 또다시 생기면 고민 없이 사용할 것 같네요!
학습 준비
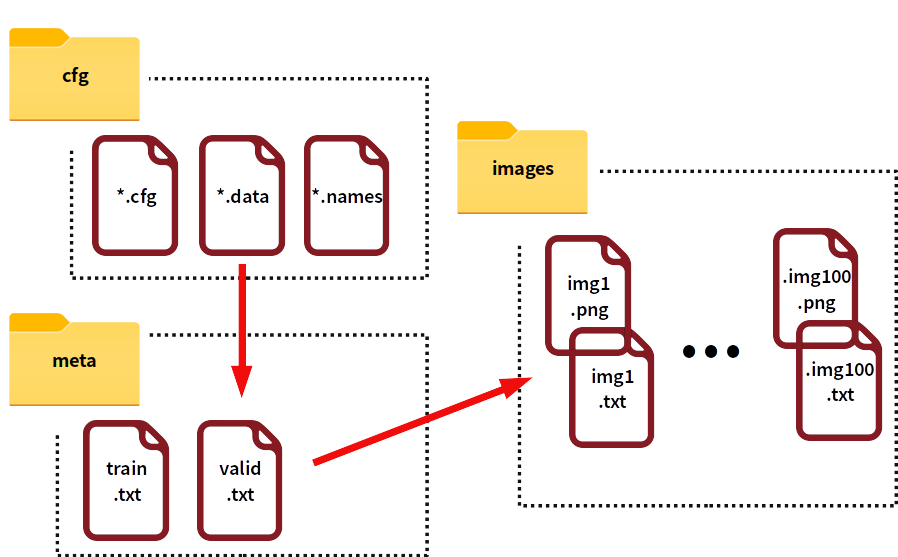
자신의 데이터셋으로 다크넷 모델을 훈련시키려면 다크넷 깃허브의 How to train (to detect your custom objects) 파트에 설명된대로 몇 가지 준비가 더 필요합니다. 개인적으로는 이 과정이 헷갈려서 제 방식대로 다시 정리를 해봤습니다. 편의를 위해 그림과 같이 meta, images 디렉토리를 생성하고, 제작한 데이터셋은 images 디렉토리에 넣어두었다고 가정하겠습니다.
meta 디렉토리 아래에는 훈련과 검증에 사용할 데이터의 목록을 작성합니다. 예를 들어 1번부터 80번 이미지를 학습용으로, 81번부터 100번 이미지를 검증용으로 사용한다면 아래와 같이 두 개의 txt 파일을 작성하면 됩니다.
images/img1.png
images/img2.png
...
images/img80.pngimages/img81.png
images/img82.png
...
images/img100.pngcfg 디렉토리에는 data, names, cfg 파일이 들어갑니다. data 파일에는 학습에 사용할 데이터와 백업 디렉토리를 정의하고, names 파일에는 데이터셋에 포함된 클래스들의 이름을 작성하면 됩니다. 예를 들어 클래스가 세 개인 데이터셋을 학습한다면 아래와 같이 작성합니다.
classes=3 # 클래스 갯수
names=cfg/cxr.names # 클래스 이름
train=meta/train.txt # 훈련용 이미지 파일 목록
valid=meta/valid.txt # 검증용 이미지 파일 목록
backup=backup # 훈련 중 가중치 백업 디렉토리ClassName0
ClassName1
ClassName2YOLO의 각 버전에는 대응하는 다크넷 cfg 파일이 존재합니다. cfg 파일은 네트워크 구조와 학습 하이퍼파라미터를 결정합니다. 원하는 버전의 설정파일을 선택한 후 사전 학습된 가중치를 다운받습니다. 물론 밑바닥부터 모델을 학습시키는 것이 불가능하지는 않지만, 이미 잘 만들어진 가중치를 굳이 활용하지 않을 이유는 없는 듯 합니다. cfg 파일과 가중치를 선택했다면 자신의 데이터에 맞게 cfg 파일을 수정합니다. 일반적으로 아래와 같은 파라미터를 조정합니다. 더욱 자세한 조정을 원하시면 깃허브 위키를 참고해주세요!
| 섹션 | 파라미터 | 설명 | 값 |
|---|---|---|---|
[convolution] |
filters |
컨볼루션 필터 갯수 | (5 + 클래스 수) * 3 |
[yolo] |
classes |
클래스 수 | 클래스 수 |
[net] |
batch |
배치 사이즈 | - |
[net] |
subdivisions |
미니배치 갯수 | - |
[net] |
max_batches |
최대 훈련 배치 갯수 | 클래스 갯수 * 2000 |
[net] |
steps |
학습률 조정 시점 | max_batches 값의 80%,90% |
학습
이제 모델을 학습시킬 준비가 모두 끝났습니다 😆 번거로운 준비과정에 비해서 학습과 성능 평가, 예측은 train, map, test 등의 간단한 커맨드만으로 수행할 수 있습니다. 조금 번거로운 준비 과정을 거쳐야 하지만 절차만 잘 지킨다면 누구나 쉽게 사용할 수 있다는 점이 다크넷의 매력인 것 같습니다!
저는 사내 데이터 2,000장으로 YOLOv3의 학습과 검증을 진행한 후 사내 데이터 200장과 오픈 데이터 200장에 대해서 각각 mAP를 테스트해보았습니다. 테스트 결과 사내 데이터에 대한 성능은 0.9998로 꽤 높았지만 오픈 데이터에 대한 성능은 0.2020 정도로 매우 낮았습니다 😞 나름대로 이런저런 augmentation을 적용해서 성능을 끌어올린 결과인데, 생각보다 훈련 데이터에 오버피팅이 많이 되어있는 듯 합니다. 역시 시간이 허락하는 한 가장 좋은 방법은 더욱 다양한 데이터를 만드는 것인가봅니다. 아래 사진은 오픈 데이터에 대한 테스트 수행 결과입니다.
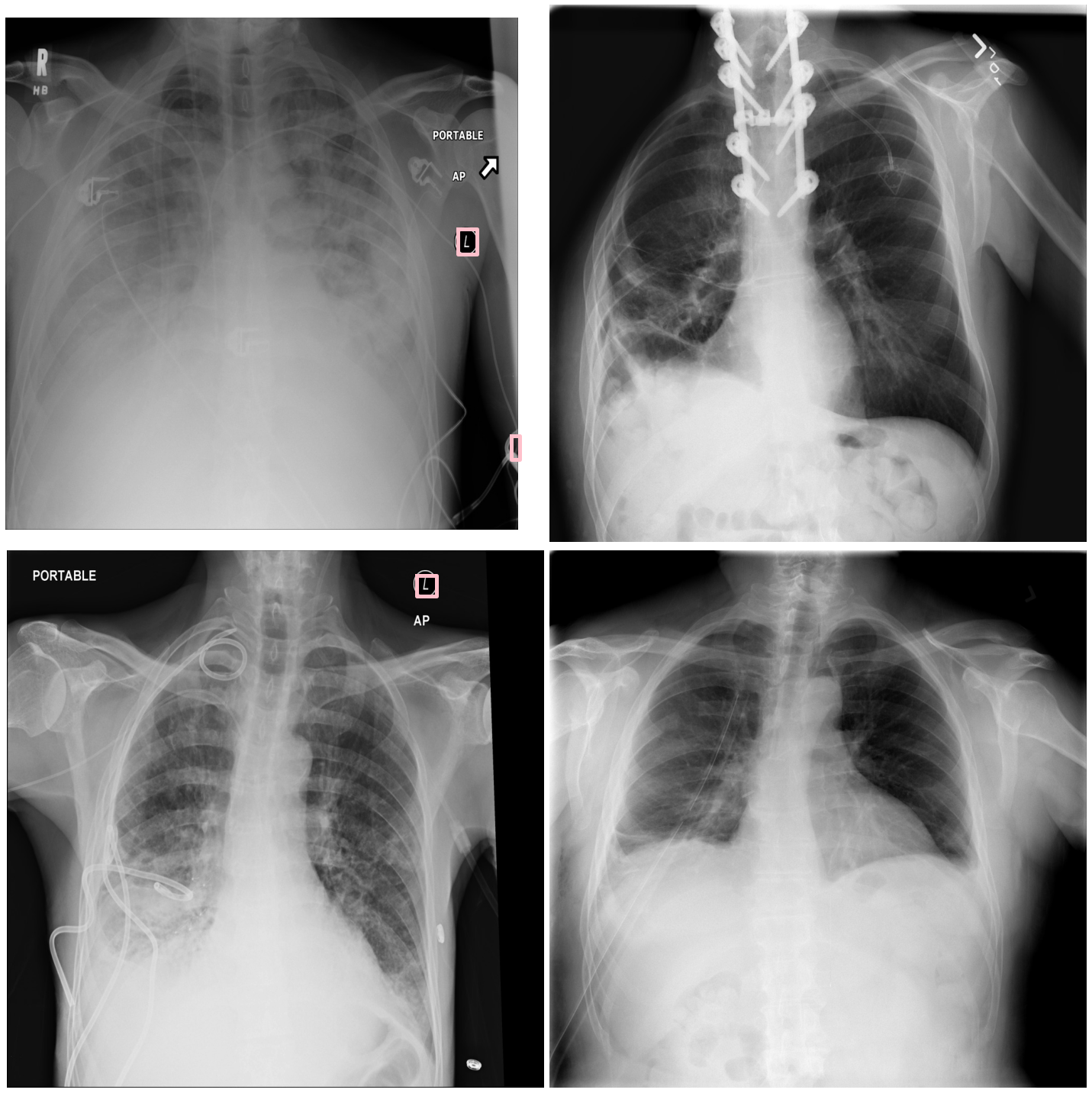
Wrap up
다크넷을 간단하게 사용해본 소감은 "귀찮지만 쉽다(혹은 쉽지만 귀찮다)" 입니다. 제 생각에 다크넷은 고난도의 태스크를 해결하기 위한 전문적 도구라기보다는 쉬운 난이도의 태스크를 해결하기 위한 범용적 도구인 것 같습니다 (YOLO의 가장 큰 장점으로 꼽히는 속도에 대해서는 사실 다른 모델을 사용해본 적이 없어서 뭐라고 말씀은 드리지 못하겠네요😅).
다크넷은 정말 쉽습니다. 다크넷의 학습 과정은 YOLO와 C에 대한 지식을 거의 요구하지 않습니다. 다크넷은 모델의 구조와 사전 훈련된 가중치를 모두 제공하기 때문에 사용자는 자신의 데이터를 준비한 후 훈련에 필요한 파일들을 만들고 수정하기만 하면 됩니다. 이 과정이 조금 번거롭기는 하지만, 가이드 문서에 설명이 상세하게 되어있기 때문에 인내심을 가지고 따라한다면 누구나 나쁘지 않은 성능을 가진 모델을 만들 수 있습니다.
하지만 이 준비 과정이 상당히 귀찮고, 반복적인 실험과 재현의 편의성 면에서 다른 프레임워크에 비해 뒤떨어집니다. 전처리 방식이나 학습 파라미터가 변경될때마다 이 준비과정을 계속 반복해야 한다고 생각하면 정말 끔찍합니다 😱 즉 가볍게 사용하기에는 좋지만, 반복적인 실험을 통한 성능 향상을 염두에 두고 있다면 조금 불편할 수 있는 프레임워크입니다. 머신러닝 모델의 성능 향상이 결국에는 수많은 실험에 기반하는 것이라면 다크넷의 단점은 꽤 치명적일수도 있지만, 1%의 성능 향상에 목숨을 걸어야 하는 상황이 아니라면 상당히 괜찮은 프레임워크이니 자신의 상황에 맞게 선택하면 될 것 같습니다!