[Self-Supervised Learning] Review: Bootstrap Your Own Latent -A New Approach to Self-Supervised Learning
![[Self-Supervised Learning] Review: Bootstrap Your Own Latent -A New Approach to Self-Supervised Learning](/content/images/size/w2000/2021/03/ssl-4.png)
최근 Self-Supervised Learning 에 관한 연구가 활발해지면서 자연스럽게 Bootstrap Your Own Latent 에도 관심을 가지고 접하게 되었다. BYOL 이 발표되기 전 까지는 아마도 MoCo 나 SimCLR 정도가 좋은 성능을 내고 있었지만, supervised learning 과 더 가까운 수준의 top-1 classification accuracy 를 보여 주는 것은 BYOL 이라고 한다.
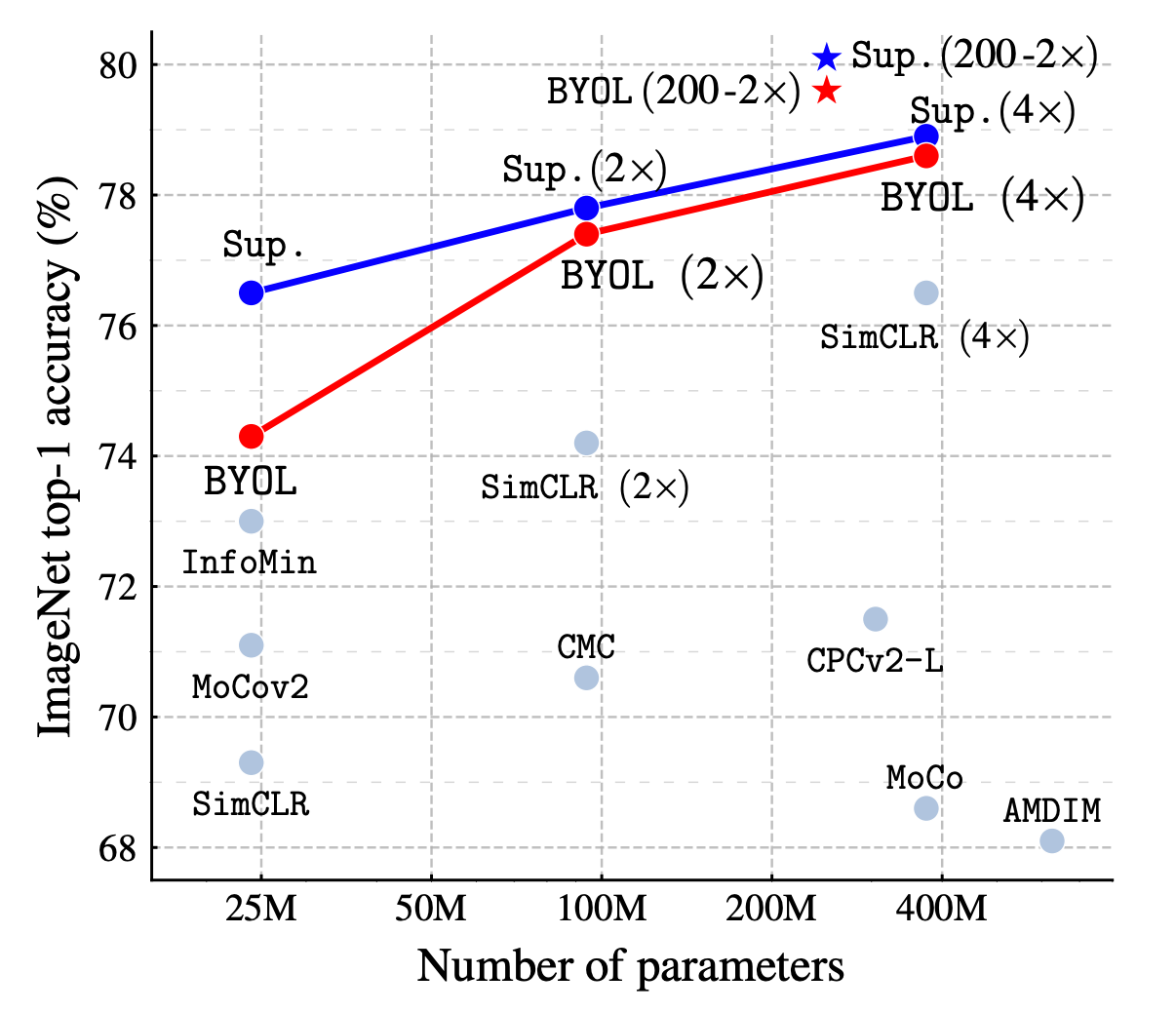
기존의 대표적인 SSL method 들을 살펴보면, 두개의 encoder network를 수반하는 구조는 비슷해 보이지만, 학습 방식의 관점에서는 매우 다른 것을 알 수 있다. BYOL 은 negative sample 에 의존하는 방식을 벗어나서 new state-of-the art 를 달성한 점을 강조하고 있다. 이 사실은 SimCLR 을 주로 사용해봤던 사람이라면 매력적으로 느껴질 수 있는데, 적은 batch size 에 대해서도 좋은 결과를 가져올 수 있다는 뜻이고, 나아가 augmentation 방식의 선택에 대해서도 다른 contrasrive learning 에 비해 robust 하다고도 볼 수 있다.
Description of BYOL
BYOL 의 구조를 보기에 앞서 MoCo 의 학습 방식을 생각해 보면, momentum encoder 는 negative sample 로 이루어진 dictionary 의 효율을 극대화하도록, 나머지 한쪽의 positive encoder 를 이용하여 특정 coefficient 만큼 시간차를 두고 업데이트 시켜주는, 다시말해 end-to-end 로 contrastive loss를 back-propagation 하지 않는 구조였다. BYOL 역시 비슷한 전략을 취하고 있음을 아래 그림을 통해 확인할 수 있다.
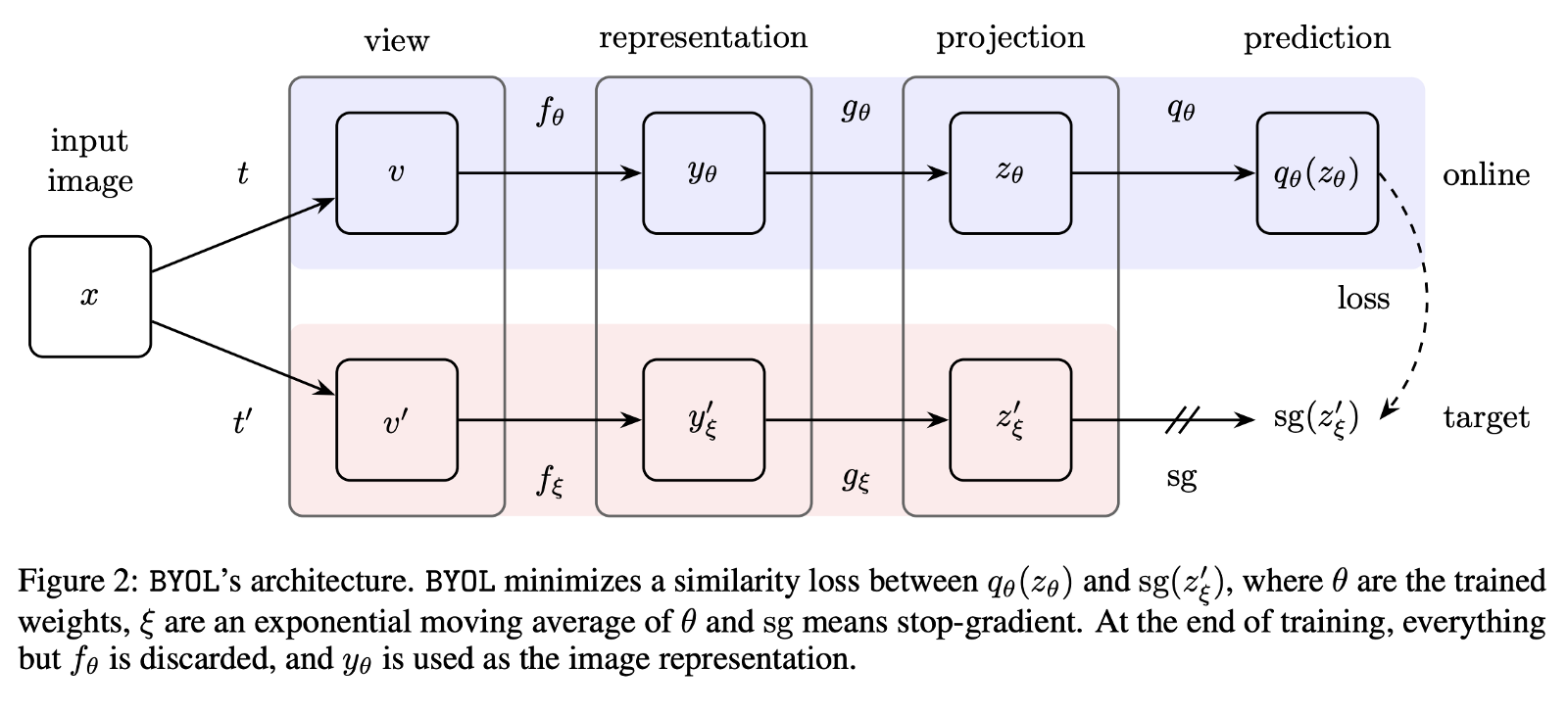
BYOL에서 두개의 network pipeline 은 위에서부터 online 및 target 으로 불리우고, θ 와 ξ 는 각 network 의 parameter 를 의미한다. 그리고, encoder 를 통과한 서로 다른 augmented view를 subspace로 projection 하고있음을 확인할 수 있다. 즉, encoder 와projection 까지 두개의 stage는 동일하다.
BYOL이 유별난점은 마지막 prediction 부분이 서로 asymmetric 하다는 점 인데, online network 는 projection 된 representation 을 한번 더 projection 시켜 주는 반면, target network 는 이 부분을 생략한 채 stop gradient , 다시말해 ξ.requires_grad = False 를 시켜주고 있음을 알 수 있다. 여기서, prediction 이라는 행위를 projection 과 동일시 한 이유는, 논문의 Figure 8에서 확인할 수 있다. 당연하게도 <qθ(zθ), z'ξ> 가 계산되려면 qθ(zθ) 과 z'ξ 의 차원이 같아야 한다는 점에서 prediction 은 차원축소도 아니다. (이 predictor 의 역할은 리뷰를 다 읽고 나면 이해가 갈지도 모르겠다.)
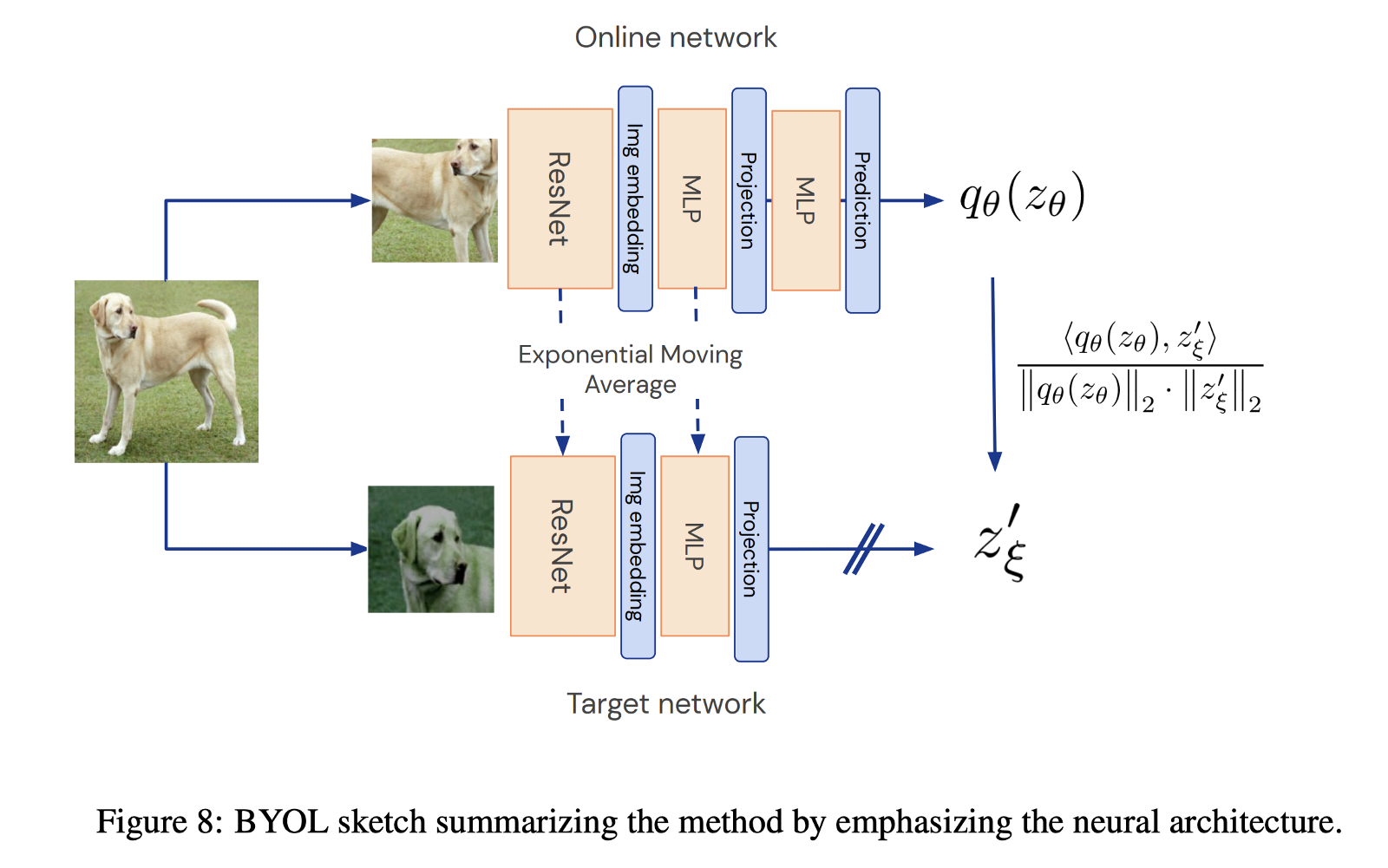
위의 Figure 8 에 기재된 term이 곧 loss function 인데, 정확히는 regression target z'ξ을 예측하기 위해 l2-normalized qθ(zθ) 및 z'ξ vector를 mean squared error 에 넣어 계산했을때 나오는 cross-term 임을 알 수 있다.
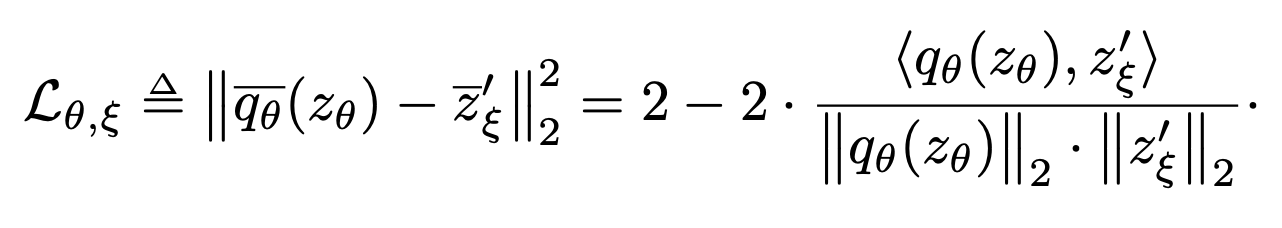
BYOL 의 최종 loss function은 symmetrized mean squared error 형태이며, 이를 최소화 하는 방향으로 학습이 진행된다. 대칭항은 처음에 online network 를 통과한 augmented view v를 target network 를 통과했던 view v’ 과 서로 바꿔주면 계산된다. 앞서 보았듯이 target network 는 stop gradient 이므로, 위 loss는 θ 에 대해서만 minimize 한다.
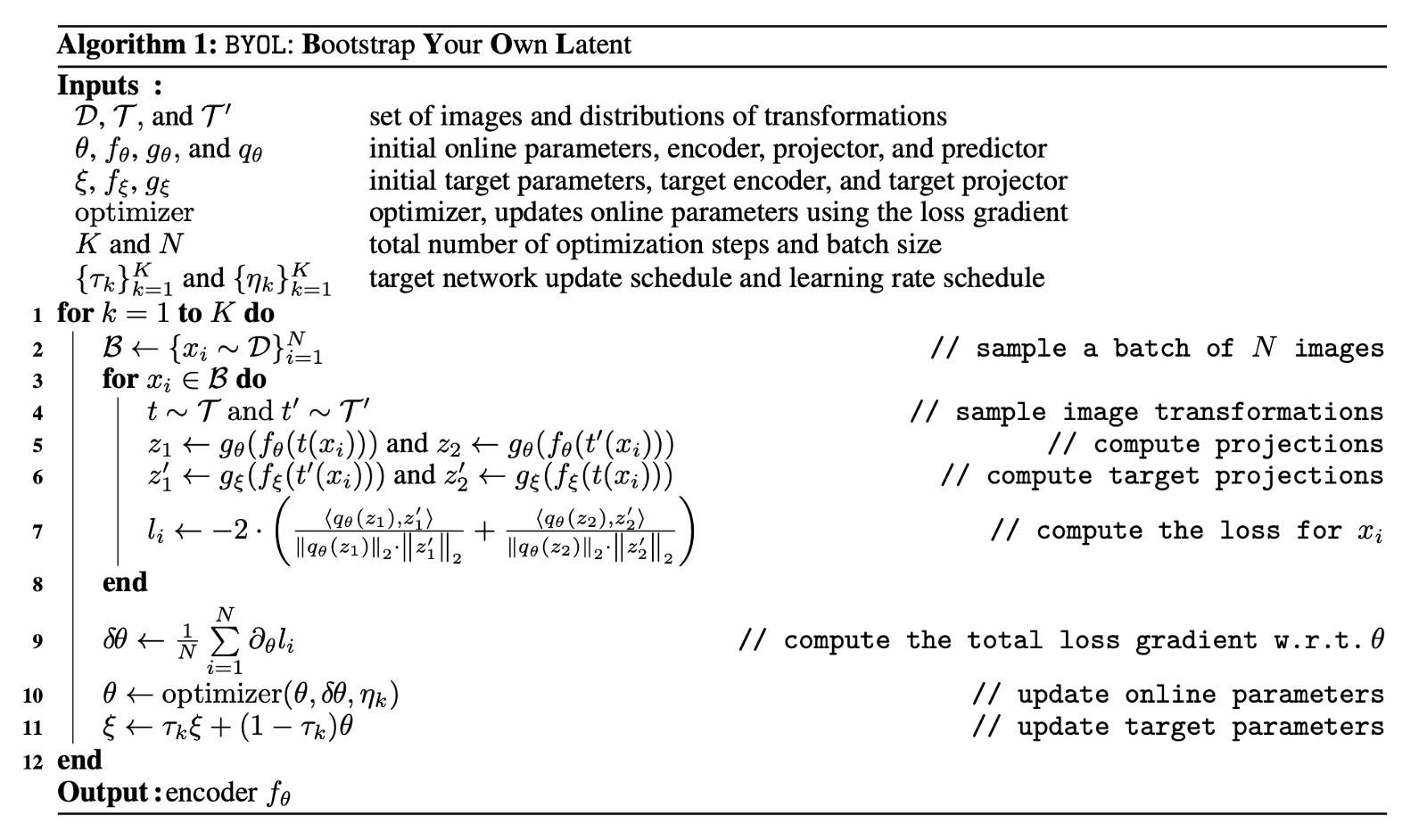
BYOL의 dynamics 를 언급할 때 하나 더 중요한 것이 Algorithm 의 11번행이다. 위에서 언급한 stop gradient 로 인해 target network 는 regression target 을 제공하는 대신, 매 training step 마다 일정 decay rate 만큼 online network 로부터 parameter 를 제공 받게 된다. 이것을 논문에서는 online parameter θ 의exponential moving average 라고 표현하고 있고, 기존의 RL 분야에서 얻은 아이디어임을 알 수 있다.
위와 같은 방식으로 parameter 를 업데이트 해주면 target network 는 변화가 늦어지기 때문에 더욱 stable 한 target 을 online network 에 제공할 수 있게 되고, 그렇기 때문에 전체적인 bootstrapping mechanism 이 supervised learning 과 같은 효과를 얻게 해주는 듯 하다. 반면, MoCo 에서의 momentum encoder 업데이트를 생각해 보면, stable 한 target 이 아닌 negative sample 들의 representation 을 consistent 하게 보존하려는 측면이 더 강했다고 생각할 수 있을 것이다.
Intuitions on BYOL’s behavior
기존의 SSL 방식들이 negative sample 에 의존했던 이유는 training 간에 발생하는 collapse 를 방지하기 위해서 였다. BYOL 은 위와 같은 mechanism 덕분에 negative sample을 사용하지 않으면서도 constant representation 으로 collapse 하지 않게 된다고 설명하고 있다. 앞서 본 target network 는 loss 로부터 back-propagation 을 하지 않으므로, loss 값은 θ 와 ξ 에 대해 jointly minimize 되지 않는다고 볼 수 있는데, GAN 의 학습방식을 떠올려 보면 이와 비슷하다는 것을 알 수있다.
그렇다면 BYOL 역시 GAN 의 mode collapse 와 같이 엉뚱한 방향으로 수렴할 가능성이 있는데, 저자들도 이러한 undesirable equilibria 의 존재를 인정하면서도, 적어도 실험적으로 아직은 collapse 를 경험해 보지 못했다고 언급한다. 이에 대해 조금 더 고급스러운 표현으로, BYOL 의 predictor 가 optimal 인 경우에는 undesirable equilibria 는 unstable 하다 는게 이들이 주장하는 바이다. 이 가설이 알고보면 정당 하다는 것을 간단히 짚고 넘어가기로 한다. 먼저, optimal predictor 는 다음과 같이 정의할 수 있다.
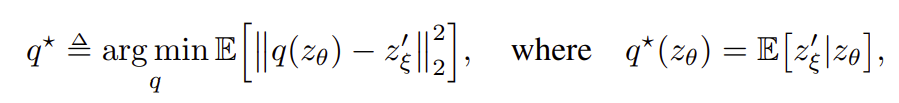
그리고, 이 정의에 따라 optimal predictor 에 의해 θ 방향의 gradient 를 계산해보면 다음과 같이 expected conditional variance 를 얻는다.
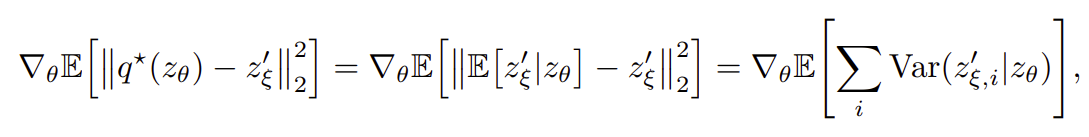
만일, optimal predictor 에 의해 representation 이 constant c로 수렴해 버렸다고 하면, zξ 와 c 의 conditional variance, 즉 Var(zξ|c) 만큼 gradient descent 가 일어날 것 이다. 그러나, 임의의 random variable 들의 conditional variance 에 관한 부등식으로 부터, 위에서 계산한 Var(zξ|zθ) 가 variability 가 가장 작은 경우인 Var(zξ|c) 보다 커지는 경우는 절대 없기 때문에, 학습 과정에서 그러한 constant 로 수렴하는 경우는 없다는 논리이다. (없다라기보다 예상컨대, 잠깐 정도는 수렴했다가도 또다른 variability 가 ξ 를 업데이트 하는 과정에서 나타난다면 다시 gradient descent 가 일어난다 정도로 이해하면 좋을 것 같다. 즉, representation 은 stable 하게 constant 로 머물려 하지 않는다.)
Building intuitions with ablations
저자들의 intuition 을 이론적으로 보았으니, 실제 실험이 보여주는 결과를 몇가지 보도록 한다. 먼저, batch size 와 augmentation 에 관한 ablation 이다.
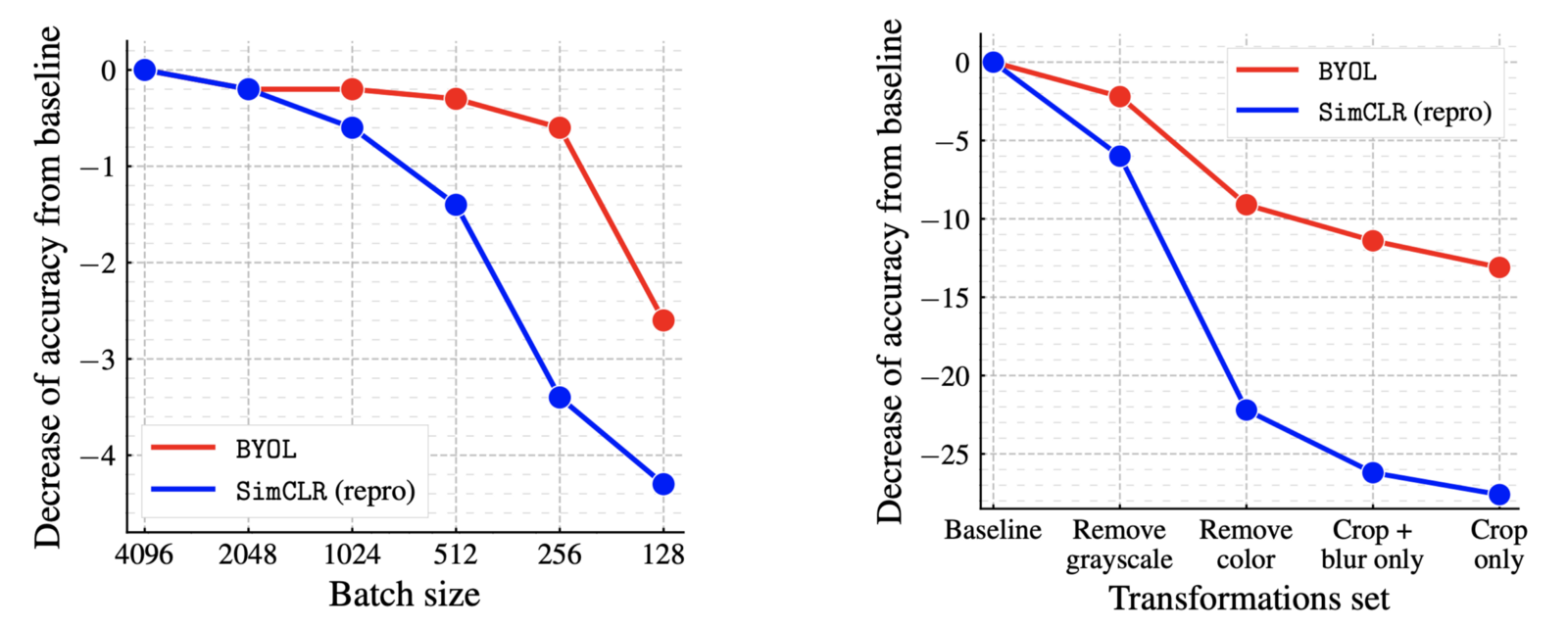
SimCLR 은 batch size 가 충분히 크지 않으면 효과를 보기 힘들지만, BYOL 은 negative sample 에 의존하지 않기 때문에 상당히 적은 양의 batch size 로도 좋은 성능을 내고 있음을 알 수 있다. 또한, transformation 을 removing 하는 과정에서도 역시 SimCLR 보다 더욱 안정적인 결과를 얻고 있다. 다음으로 decay rate 가 주는 효과 및 contrastive method 와의 비교 실험 결과를 보자.
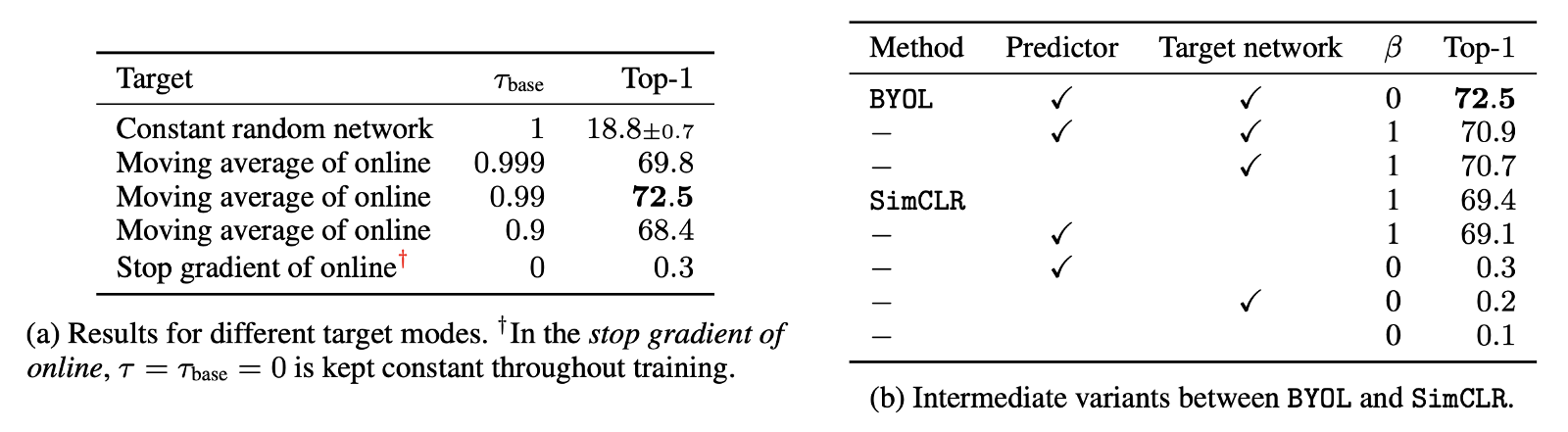
왼쪽 table 은 decay rate 를 바꾸어 가며 top-1 accuracy 를 측정한 결과인데, 당연하게도 τ=0 인 경우, target network 는 매 training step 마다 ξ <- θ 로 바로 치환되기 때문에 매우 좋지 않은 결과를 얻고, τ=0.99 인 경우에 가장 높은 accuracy 를 얻었다.
오른쪽 table 은 contrastive loss, predictor 및 target network 의 유무에 따른 ablation 을 나타내고 있다. β=1 인 경우가 일반적인 InfoNCE loss 이고, β=0 이 BYOL 의 loss function 이라고 생각하면 되겠다. 다시말해, BYOL 의 loss 는 InfoNCE 의 특수한 경우인 것이다. (정확히는 β=0 인 경우가 negative sample 을 사용하지 않는 다는 말과 상통하는데, 자세한 설명은 Appendix F.4 를 참조하기 바란다.)
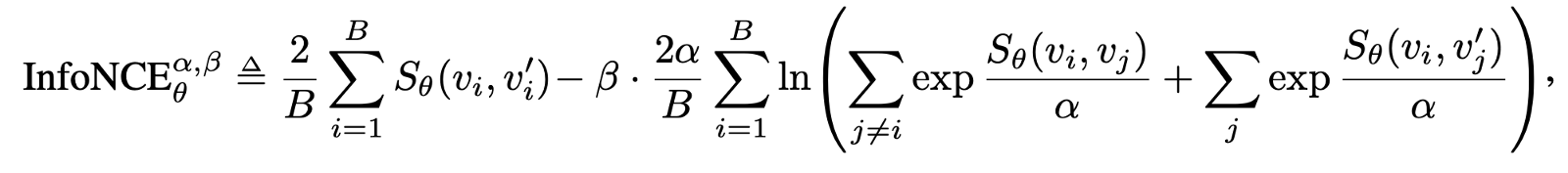
이 실험을 통해 다시한번, negative sample 에 의존하지 않으면서도 가장 좋은 representation 을 얻기 위한 유일한 variant 는 β=0 으로 설정하고 predictor 와 target network 를 모두 사용한, 즉 BYOL 이라는 것을 알 수 있다.
Conclusion
이번 포스트를 통해 기존의 contrastive learning 의 단점을 다시한번 파악하면서, BYOL 이라는 새로운 방식의 SSL 에 대해 리뷰해 보았는데, 아직은 이해가 미숙한 부분이 많은 듯 하다. 저자들은 아직 BYOL 이 vision application 에 특화된 기존의 augmentation 에 의존적이라고 하나, negative sample 을 이용하지 않고서 SOTA 를 달성 했다는 점만으로도 시사하는 바는 크다고 생각한다.
(잘못된 내용이나 의견을 달아주시면 수정하도록 하겠습니다.)
 Seungmin Ha
Seungmin Ha