[GAN 시리즈][StyleGAN] A Style-Based Generator Architecture for Generative Adversarial Networks -2편

![[GAN 시리즈][StyleGAN] A Style-Based Generator Architecture for Generative Adversarial Networks -2편](/content/images/size/w2000/2020/11/title.png)
- StyleGAN은 PGGAN 구조에서 Style transfer 개념을 적용하여 generator architetcture를 재구성 한 논문입니다. 그로 인하여 PGGAN에서 불가능 했던 style을 scale-specific control이 가능하게 되었습니다.
- Paper 원문: StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks
- StyleGAN official code(Tensorflow): https://github.com/NVlabs/stylegan
- 본 포스팅은 StyleGAN 2편으로 StyleGAN 1편을 읽고 오시면 이해하기 더 좋습니다.
StyleGAN 1편에서는 entangle, disentangle가 어떤 의미인지, StyleGAN의 기초가 되는 PGGAN의 특징과 단점을 알아보고 그 단점을 개선하기위해 StyleGAN의 특징은 어떤지 알아보았습니다. 이번 블로그 포스팅에서는 latent space가 disentangle한지 정량화 하기 위한 measure들을 소개하고 styie mixing regularization와 같은 스킬 및 장점들에 대해서 알아보도록 하겠습니다.
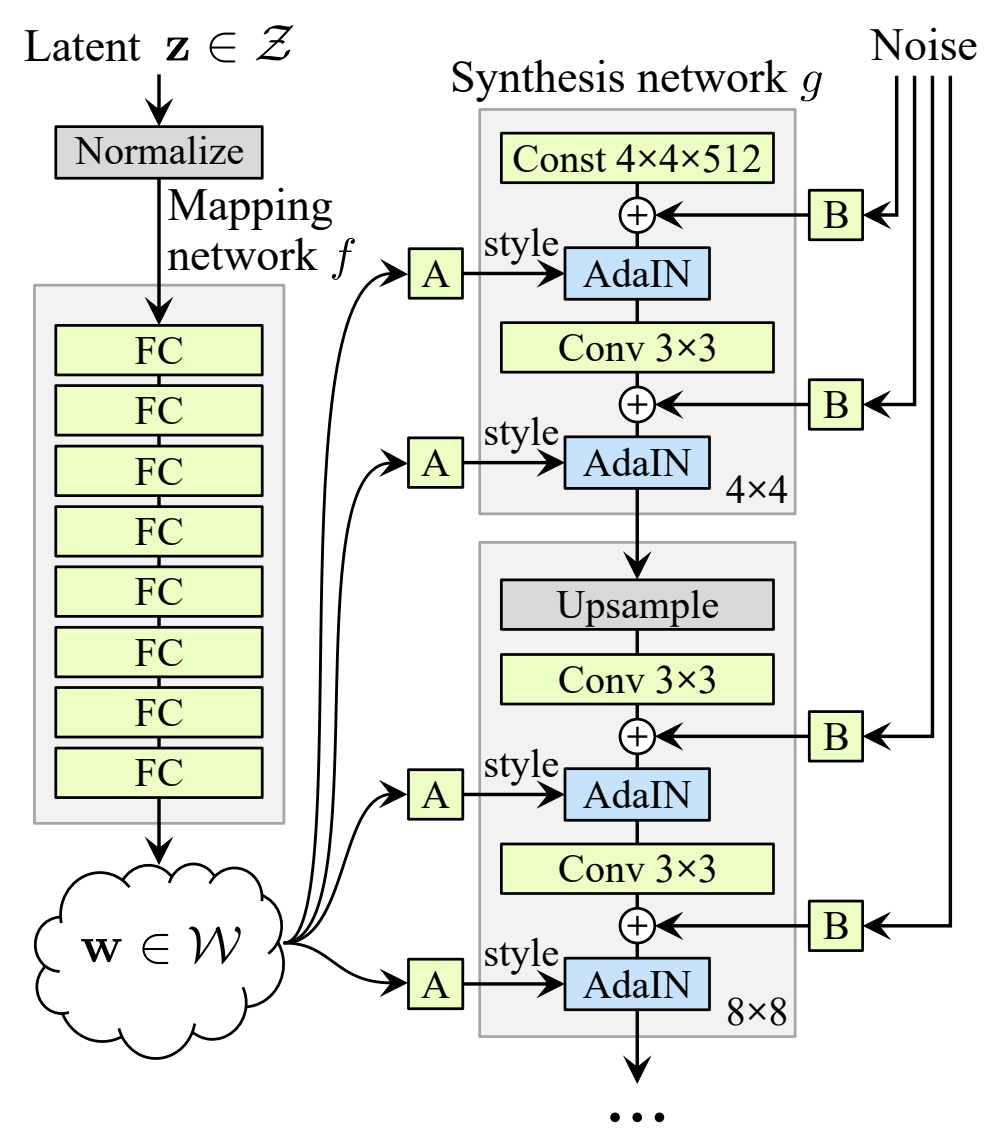
4. Properties of the style-based generator
4-1. Style mixing
single Latent \( z\) 이용할 경우 특징
StyleGAN에서 동일한 latent vector \( z\)가 Mapping network \( f\)를 통해서 나온 \( \mathcal{W}\) 하나만 계속 네트워크를 학습하다보면 correlation이 발생하며 학습이 되는 문제가 발생하게 될 수 있습니다.
한번 예시를 들어보도록 하겠습니다.
학습 데이터셋에서 극히 드물게 대머리인 사람은 항상 선글라스를 착용하고 있는 데이터가 있을 때 GAN은 학습 데이터의 분포와 비슷한 분포를 갖도록 학습하다보니 Generator은 선글라스 == 대머리 라는 correlation이 발생하여 무조건 대머리인 사람은 선글라스를 착용한 상태로 생성하는 overfitting이 일어날 가능성이 많아집니다.

multi Latent \( z\) 이용할 경우 특징
style correlation이 발생하지 않고 학습을 진행하기 위해서는 synthesis network을 학습 시킬 때 하나의 Latent vector \( z\)에서 나온 \( \mathcal{W}\)을 이용해서 학습 하는것이 아니라 latent space에서 뽑은 \( z_1\), \( z_2\), ... \( z_n\)을 mapping network \( f\)에 통과시켜서 \( w_1\), \( w_2\), ... \( w_n\)을 만듭니다. 이후 (그림 2)와 같이 50:50 비율로 나눠서 각 layer에 적용해도 되고 다른 비율로 상황에 따라 적용하면 됩니다.
이런 style mixing 방법을 사용하면 다양한 style이 섞여서 synthesis network 학습이 됩니다. 따라서 Generator을 이용해서 이미지 생성을 해보면 style correlation이 거의 없으며 입력할 때 AdaIN을 통해 입력을 하게 되므로 regularization 효과도 볼 수 있게 됩니다.
그 결과 (그림 3)처럼 style correlate되는 현상을 방지해서 각 layer에 해당하는 style들이 잘 구분되면서 적용되는 것을 볼 수 있습니다.

4-2. Perceptual path length
latent space가 disentangle 하다는 것을 정량화 하기 위해 본 논문에서는 다음과 같은 두가지 measure를 제안했습니다.
- perceptual path length
- linear separability (설명 생략)
latent space에서 (그림 4)처럼 blue point → red point로 변화을 주면서 생성한 이미지들의 특징(e,g,. 머리 색이 변경했는지, 없던 점이 생겼는지)들이 사람이 봤을 때 "어떤 특징들만 변화 하였는지"를 잘 구분을 할 수 있는지에 대한 방법을 자동화 시켜서 perceptual path length 라는 개념을 제안 했습니다.
측정 방법
지금까지 생성된 이미지들간 거리가 얼마나 떨어져 있는지 알아보는 방법으로 L2-distance를 이용했지만 perceptual path length은 이미지들을 잘 구분하도록 학습된 pretrained model을 이용해서 입력 이미지가 들어오면 그 이미지가 어떤 이미지인지 처리하기 위해 본 논문에서는 VGG16 모델을 사용하고 있습니다.
이미지가 어떤 이미지인지 잘 구분하는 pretrained model의 중간 레이어의 feature map은 마지막 레이어 보다 이미지에 대한 더 많은 정보들을 가지고 있으니 embedding된 중간 레이어의 feature map을 사용하여 perceptual path length을 구하게 됩니다. 이 역할은 사람이 여러 이미지들에서 어떤 특징들이 변화하였는지 잘 구분하는 과정과 동일하다고 이해하시면 됩니다.

perceutpal path length는 \( G(z_1)\)와 \( G(z_1+\epsilon)\)을 pretrained VGG16에 각각 embedding 시켰을 때 VGG16 내에서 embedding 되는 pairwise image distance을 구하는 방법입니다. 만약 \( \epsilon\)의 변화룰 주면서 생성되는 이미지 \( G(z_1+\epsilon\)와 \( G(z_1)\)의 변화가 크다면 pairwise image distance 값도 커지게 되며 latent space가 entangle하다고 볼 수 있습니다.
극단적으로 예시를 들어보도록 하겠습니다.
(그림 5, b)는 학습 데이터셋의 분포를 억치로 끼어맞추기 형식으로 만든 latent space \( \mathcal{Z}\)입니다. 그림을 보면 선(line)들이 규칙적이지 않고 불규칙하게 좁았다가 넓었다가 하는 것을 볼 수 있습니다. 저런 latent space에서 \( z\)을 변형하면 남자 였다가 갑자기 성별이 확 변하는 것 처럼 사람이 봐도 많이 변했다는 것을 인지할 수 있을 정도로 이미지가 변하게 됩니다. 이런 상태를 latent space가 entangle하다 라고 말을 한 경우입니다.
근데 본 논문에서는 latent space가 disentangle하게 하기 위해서 Mapping network \( f\)을 거쳐서 학습 분포와 비슷한 형태로 처음부터 mapping 한 latent space \( \mathcal{W}\)을 이용해서 모델을 학습하게 됩니다. (이때 더 disentangle 하게 만들기 위해서 style mixing 기법을 사용하게 됩니다.) disentangle한 latent space에서 \( w\)값을 변화해주면 특징 각 scale마다 담당하고 있는 특징들만 변화하게 됩니다. 이를 latent space가 disentangel하다 라고 말을 합니다.

4-3. 원하는 부분을 미세하게 변형하기
StyleGAN은 화가들이 미술 작품에서 특정 부분만 리터치 하는 것 처럼 머리카락 내려갔는데 이것을 살짝 올려줄 수 있습니다. 마치 인공지능계의 화가가 리터칭 하는거와 같은 의미인거죠
전통적인 Generator은 \( z\) 하나로 입력되기 때문에 미세한 특정 부분만 변경을 해줄 수 없다는특징이 있습니다. 하지만 StyleGAN은 각 해상도마다 style을 담당하는 layer에 Mapping network을 거쳐서 나온 \( w\)을 넣어주는 형식으로 구성 되어있어서 가능합니다.
(그림 1)을 보면 style을 담당하는 \( w\)을 AdaIN을 통해 입력해줄 뿐만 아니라 Noise가 별도로 입력 되는것을 볼 수 있습니다. 이는 랜덤하게 noise를 입력시켜주면서 (그림 6)와 같이 현재 style에서 화가가 리터칭 하듯이 인공지능이 리터칭 하는것 처럼 만들어 줍니다.

5. 한계점
StyleGAN의 한계점은 (그림 7)와 같이 생성된 이미지들을 살표보니 물방울 형태의 blob들이 관측이 된다는 점 입니다.
이 한계점은 StyleGAN paper에는 안나와있고 StyleGAN2에 언급이 되어 있습니다.

6. Conclusion
High resolution Image Generation하는 GAN 논문 중 StyleGAN은 전통적인 방식과 다르게 각 style을 담당하는 layer에 style \( w\)을 AdaIN을 통해서 입력해주는 방법으로 학습 함으로 써 원하는 style로 변형을 시켜줄 수 있는 모델이며 특히 높은 성능 향상을 보여주었습니다. 또한 latent space가 disentangle하게 되기 위해서 Mapping Network를 사용한 점이 인상 깊은 논문이라고 생각합니다.