TorchIO를 이용한 3D Segmentation

안녕하세요, 프로메디우스 ML팀 인턴사원 유환승입니다. 이번 포스팅에서는 Pytorch를 기반으로 한 TorchIO를 통해 간단하게 3D segmentation을 진행하는 튜토리얼을 진행해보려 합니다.
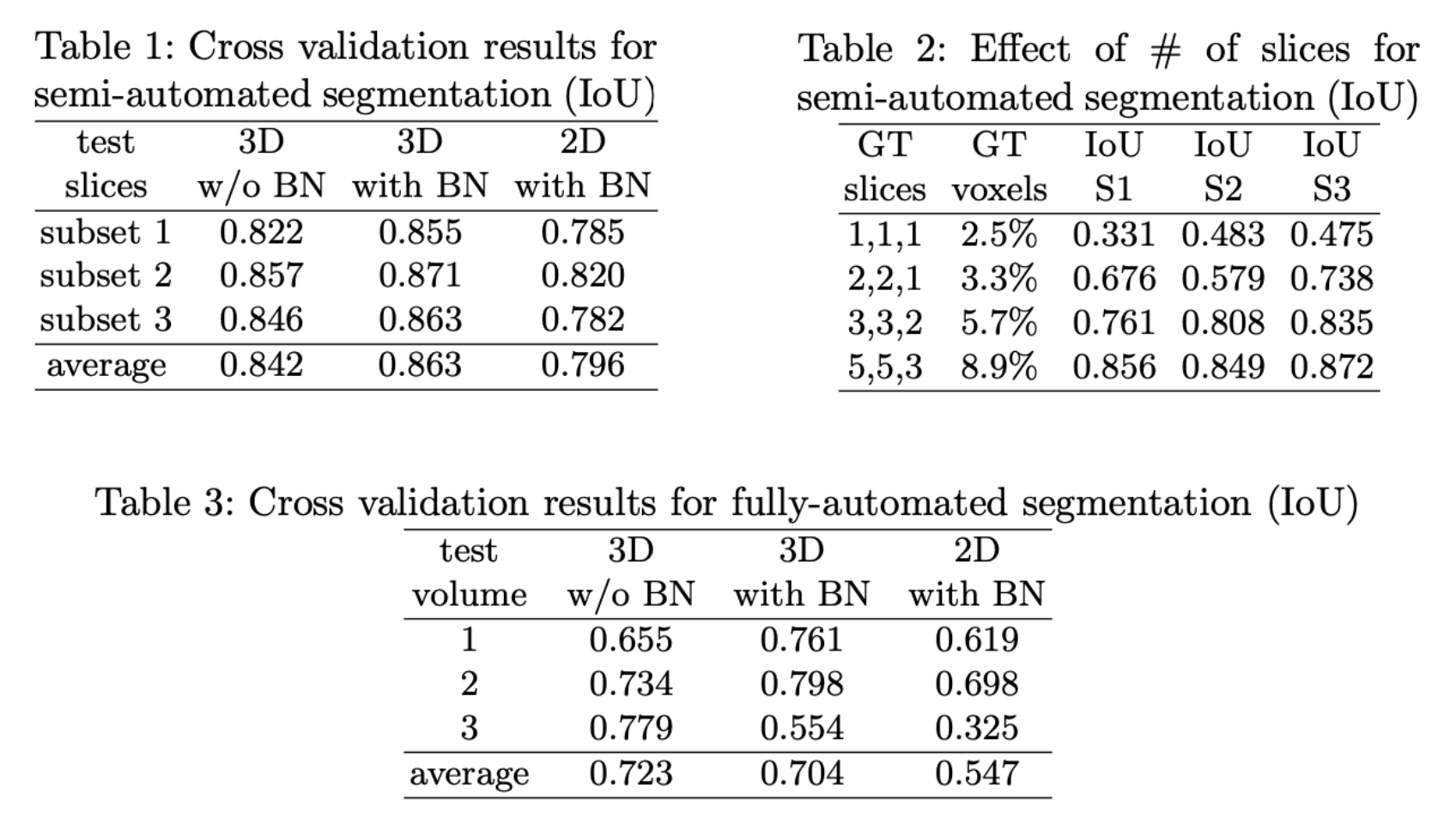
위의 Table은 3D U-Net : Learning Dense Volumentric Segmentation from Sparse Annotation에서 소개된 성능입니다. 2D segmentation에 비해서 상대적으로 3D를 통한 Segmentation 성능이 더 좋음을 확인할 수 있었습니다.저는 3D segmentation을 사용하기 쉽게 도와주는 TorchIO를 이용하여 code를 작성할 예정입니다.
Custom Dataset
def Dataset_load(base_path, mask_path, mode):
dataset_dir = Path(base_path)
maskset_dir = Path(mask_path)
images_dir = dataset_dir / mode / 'Img/'
labels_dir = maskset_dir / mode / 'Mask/'
image_paths = sorted(images_dir.glob('*.nii.gz'))
label_paths = sorted(labels_dir.glob('*.nii.gz'))
print(len(image_paths), len(label_paths))
assert len(image_paths) == len(label_paths)
MRI = 'mri'
LABEL = 'label'
subjects = []
for (image_path, label_path) in zip(image_paths, label_paths):
subject = tio.Subject(
MRI = tio.ScalarImage(image_path),
LABEL = tio.LabelMap(label_path),
)
subjects.append(subject)
dataset = tio.SubjectsDataset(subjects)
return datasetTorchIO에서도 Pytorch와 유사한 방식으로 Dataset을 구현함을 확인할 수 있습니다. Subject단위로 묶어 데이터와 라벨로 묶어 Dataset을 구현합니다. 여기서 저는 ScalarImage와 LabelMap의 차이를 제대로 몰라 고생을 좀 했었는데, 중요한 부분이라고 생각이 됩니다. 좀 더 진행이 되면 Training Data에 대해 Overfitting을 줄이기 위한 Method 중 하나로, Training data에 대해 Augmentation을 진행하게 됩니다. 여기서 Augmentation중 공간적인 변형(Spatial Transform)과 Scale에 대한 변형(Intensity Transform)이 존재하는데, Spatial Transform의 경우 Label에도 똑같이 적용이 돼어야 합니다. TorchIO에서는 Subject단위로 묶고 LabelMap도 똑같이 적용이 되게 됩니다.
TorchIO Augmentation
- Spatial Transform : LabelMap에도 똑같이 적용
- Intensity Transform : LabelMap에는 적용x
from torchio.transforms import (
RandomFlip,
RandomAffine,
RandomElasticDeformation,
RandomNoise,
RandomMotion,
RandomBiasField,
RescaleIntensity,
Resample,
ToCanonical,
ZNormalization,
CropOrPad,
HistogramStandardization,
OneOf,
Compose,
)
training_transform = tio.Compose([
tio.ToCanonical(),
tio.Resample(4),
tio.CropOrPad((64,64,48)),
tio.RandomMotion(p=0.2),
tio.RandomBiasField(p=0.3),
tio.RandomNoise(p=0.5),
tio.RandomFlip(axes=(0,)),
tio.RandomAffine(),
ZNormalization(),
])
validation_transform = tio.Compose([
tio.ToCanonical(),
tio.Resample(4),
tio.CropOrPad((64,64,48)),
ZNormalization(),
])TorchIO에서는 다양한 Augmentation 기법들을 이용하기 쉽게 구현해두었습니다. 자세한 Augmentation의 적용에 대해서는 TorchIO github에 그림과 함께 잘 설명 돼 있어서 Custom Data과 고려하여 적용하면 좋을 것 같습니다.
TorchIO : https://github.com/fepegar/torchio
training_batch_size = 4
validation_batch_size = 2 * training_batch_size
training_loader = torch.utils.data.DataLoader(dataset = training_set, batch_size = training_batch_size, shuffle = True,
num_workers=0)
validation_loader = torch.utils.data.DataLoader(dataset = validation_set, batch_size = validation_batch_size,
num_workers=0)
Model, Loss, Optimizer
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
CHANNELS_DIMENSION = 1
SPATIAL_DIMENSIONS = 2,3,4
class Action(enum.Enum):
TRAIN = 'Training'
VALIDATE = 'Validation'
def prepare_batch(batch, device):
inputs = batch['MRI'][tio.DATA].to(device)
foreground = batch['LABEL'][tio.DATA].type(torch.float32).to(device)
background = 1 - foreground
targets = torch.cat((background, foreground), dim = CHANNELS_DIMENSION)
return inputs, targets
def get_dice_score(output, target, epsilon = 1e-9):
p0 = output
g0 = target
p1 = 1 - p0
g1 = 1 - g0
tp = (p0 * g0).sum(dim = SPATIAL_DIMENSIONS)
fp = (p0 * g1).sum(dim = SPATIAL_DIMENSIONS)
fn = (p1 * g0).sum(dim = SPATIAL_DIMENSIONS)
num = 2 * tp
denom = 2 * tp + fp + fn + epsilon
dice_score = num / denom
return dice_scoredef get_dice_loss(output, target):
return 1 - get_dice_score(output, target)
def forward(model, inputs):
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category = UserWarning)
logits = model(inputs)
return logits
def get_model_and_optimizer(device):
model = UNet(
in_channels = 1,
out_classes = 2,
dimensions = 3,
num_encoding_blocks = 4,
out_channels_first_layer = 32,
normalization = 'batch',
padding = True,
activation = 'PReLU',
).to(device)
optimizer = torch.optim.SGD(model.parameters(), lr = 1e-3, momentum = 0.9)
return model, optimizer저는 Model로 3d U-Net을 사용하고 Loss function으로는 Dice-Loss를 사용하였습니다. 이것 또한 Custom Data에 맞춰 다양하게 바꿔가면서 사용할 수 있을 것으로 생각됩니다. TorchIO 공식 Tutorial에서는 Train loss와 Validation loss를 tqdm을 통해서 학습 중에 확인을 할 수 있도록 구성을 해두었는데, 저의 경우에는 시각적인 graph가 더 눈에 잘 들어와서 이 부분에 대한 CODE로 수정하였습니다.
train_loss, valid_loss = train(num_epochs, training_loader, validation_loader, model, optimizer,'whole_images')Result
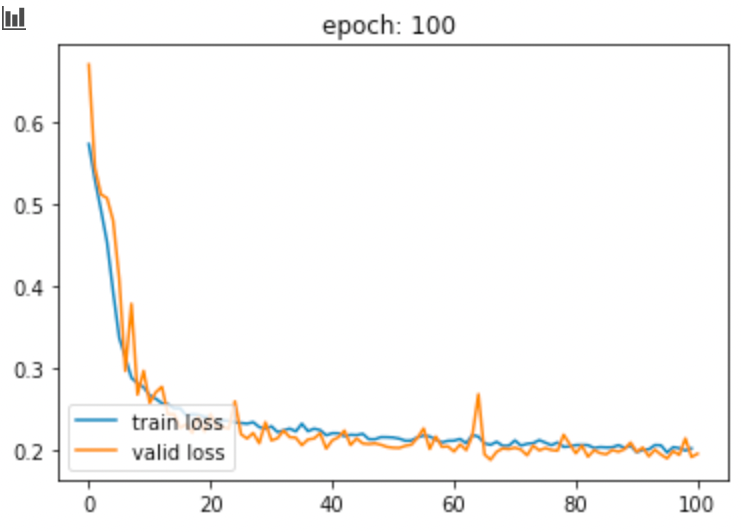
해당 결과는 3d를 Resample하여 사용하였지만, TorchIO 공식 튜토리얼에서는 Patch를 통해 학습하여 Aggregation하는 Method도 잘 소개돼 있습니다. 3D를 그대로 활용할 경우, GPU memory를 상당히 차지하기 때문에 이에 대해서 Patch 방식으로 학습하는 것도 좋은 방법으로 생각됩니다.