CycleGAN을 이용한 X-ray 이미지 style transfer
목표
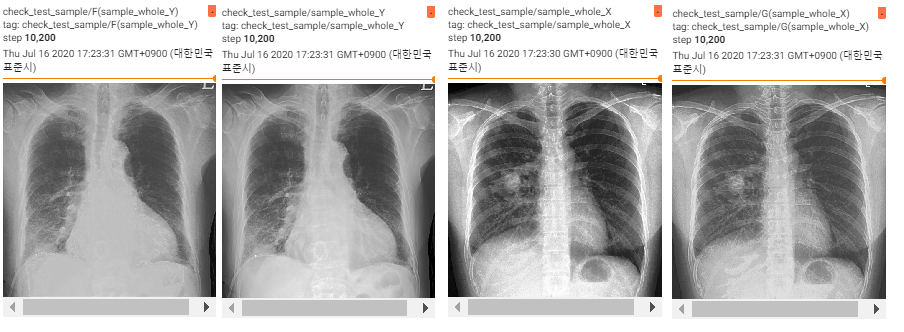
의료 영상은 사용자에 따라 선호하는 스타일이 있습니다. 그렇다보니 영상 데이터를 이용하는 경우 문제점이 발생합니다. 예를 들어 머신러닝을 진행할 때 영상 별 스타일 차이로 인해 학습이 제대로 이루어지지 않을 수 있습니다. 이러한 문제점을 해결하기 위해 CycleGAN을 이용하여 각 style domain 사이의 style transfer 작업을 해주는 모델을 만들고자 했습니다. style transfer가 제대로 이루어진다면 머신러닝 외에도 사용자의 선호에 맞는 스타일로 데이터를 제공할 수 있어서 불필요한 재촬영 등을 줄여 비용을 절약할 수 있을 것입니다.
CycleGAN
CycleGAN은 구하기 어려운 paired data가 아닌 unpaired data를 이용하여 image-to-image translation을 가능하게 하는 모델입니다. 기존의 GAN과 달리 두 개의 generator와 discriminator를 이용하는 모델입니다.
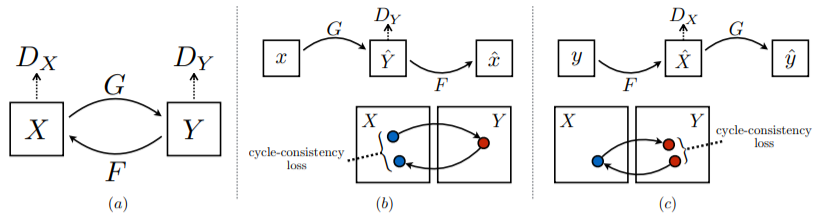
Loss
구현에서는 다음과 같이 loss를 정의하였습니다.
#### Loss
# generator loss
cycle_loss = md.cycle_loss(patch_X, F_GX, patch_Y, G_FY, args.L1_lambda)
identity_loss = md.identity_loss(patch_X, G_Y, patch_Y, F_X, args.L1_gamma)
G_loss_X2Y = md.least_square(D_GX, tf.ones_like(D_GX))
G_loss_Y2X = md.least_square(D_FY, tf.ones_like(D_FY))
G_loss = G_loss_X2Y + G_loss_Y2X + cycle_loss + identity_loss # GAN LOSS
# discriminator loss
D_loss_patch_Y = md.least_square(D_Y, tf.ones_like(D_Y))
D_loss_patch_GX = md.least_square(D_GX, tf.zeros_like(D_GX))
D_loss_patch_X = md.least_square(D_X, tf.ones_like(D_X))
D_loss_patch_FY = md.least_square(D_FY, tf.zeros_like(D_FY))
D_loss_Y = (D_loss_patch_Y + D_loss_patch_GX)
D_loss_X = (D_loss_patch_X + D_loss_patch_FY)
D_loss = (D_loss_X + D_loss_Y) / 2CycleGAN에서는 3가지 loss를 사용합니다.
- generator loss & discriminator loss
기존의 gan처럼 generator가 생성한 이미지를 discriminator가 구별하는 정도를 이용하는 loss
- cycle-consistency loss
수식으로 예를 들면 F(G(X)) 처럼 하나의 도메인에서 다른 도메인으로 생성된 이미지를 다시 원래 도메인을 전환했을 때 기존의 style이 유지되는 정도를 이용하는 loss
- cycle-identity loss
F(X)처럼 input이 원래 속한 도메인으로 생성했을 때 제대로 생성되어야 한다고 가정하고 사용하는 loss
결과
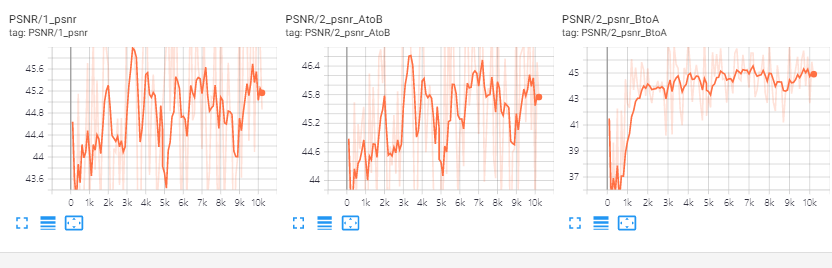
데이터의 원본은 1024*1024 이지만 메모리 부족의 문제로 patch로 잘라서 학습을 진행하였습니다.
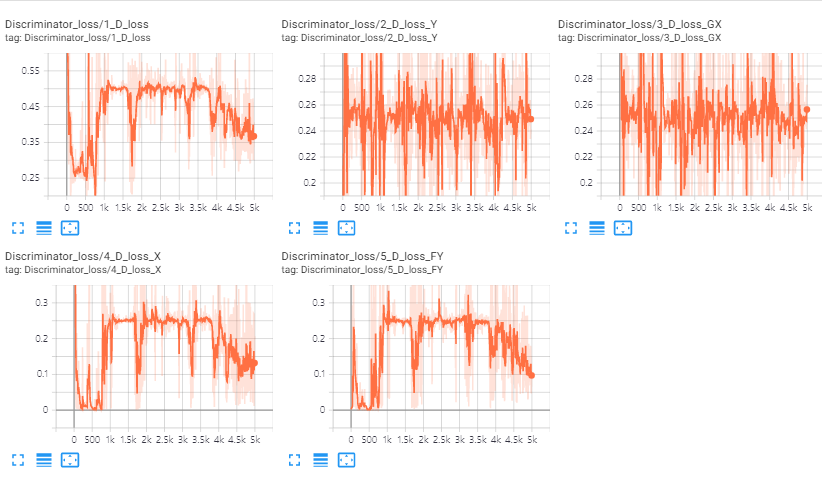
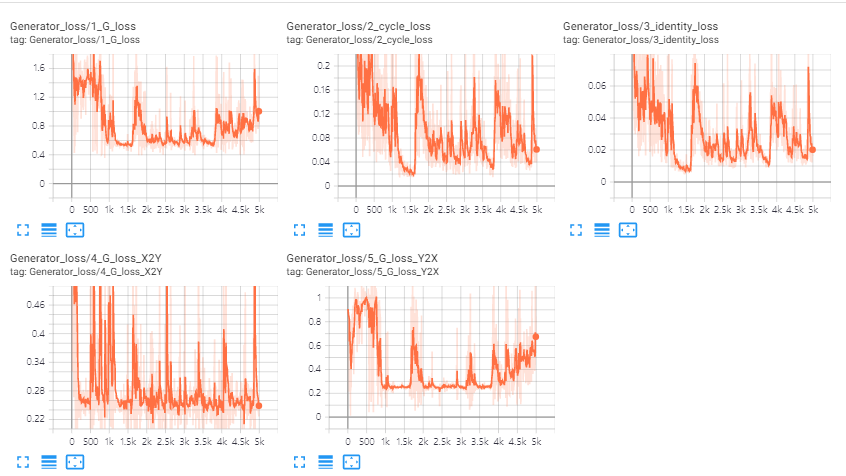
discriminator loss이 너무 작다는 것은 생성된 이미지가 실제와 다르다는 의미이므로 좋지 않습니다. 실험 결과 patch size를 작게 했을 때 discriminator loss가 상대적으로 더 낮은 값을 가지는 것을 볼 수 있었습니다.
generator loss의 경우는 patch size가 클 때 더 작은 값을 갖는 것을 볼 수 있었습니다.
batch의 크기보다 patch의 크기를 크게하는 것이 학습에 더 중요하다고 생각됩니다. 그리고 domain 별로 500장의 이미지를 사용했는데 하나의 style의 분포를 표현하기에는 부족한 양이라고 생각됩니다.
cycleGAN은 unpaired data를 가정하지만 주어진 data는 paired data인 만큼 paired data의 장점을 활용하면 더 좋은 결과를 얻을 수 있을 것 같습니다.
- patch size : 64*64 batch size : 16
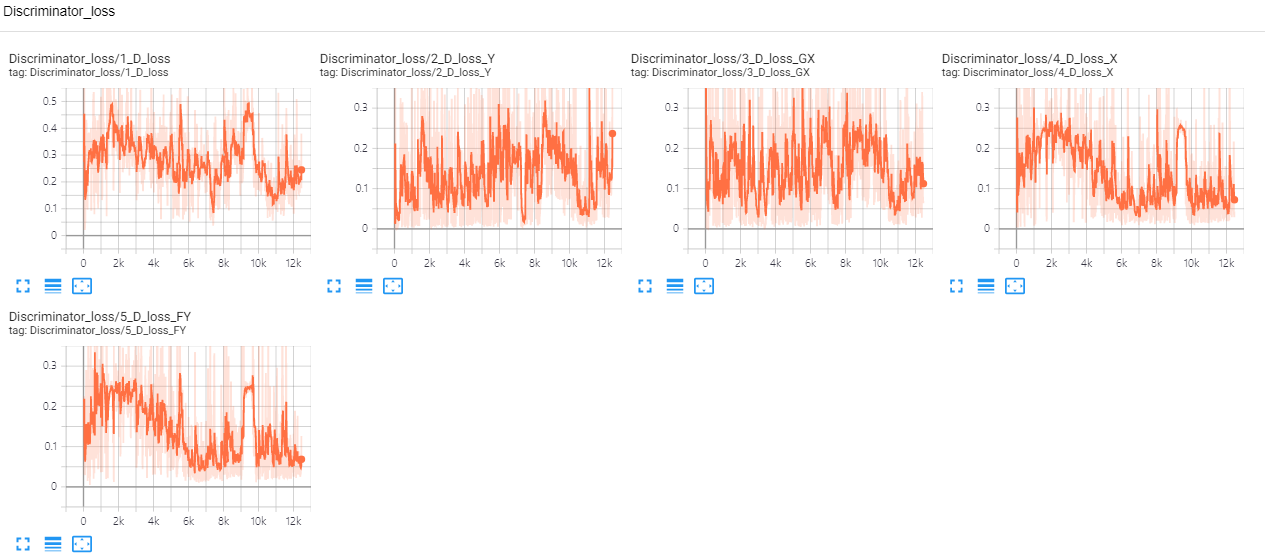
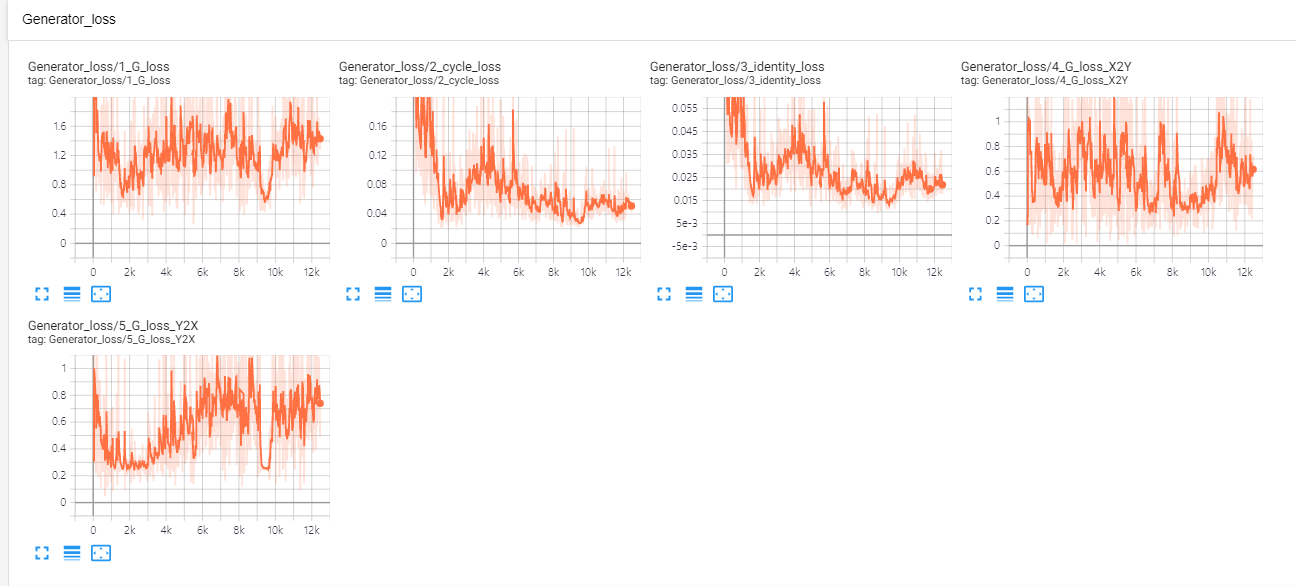
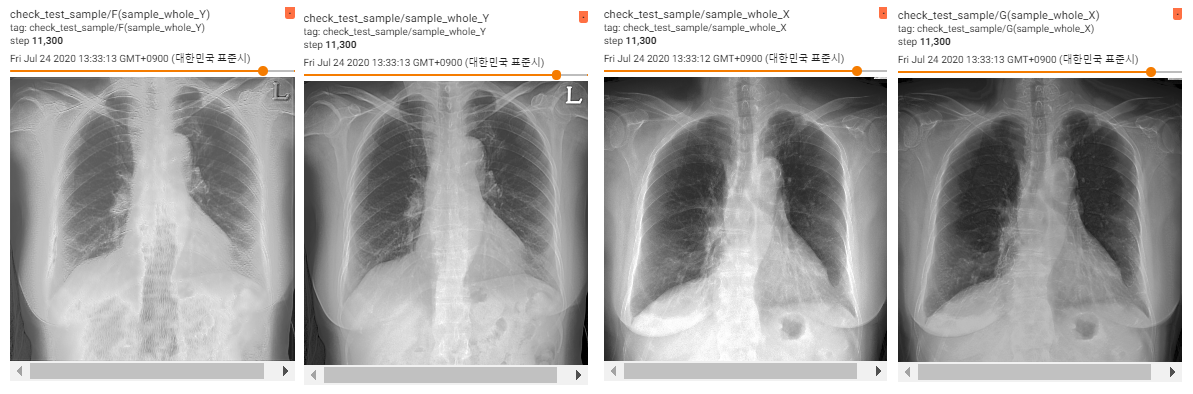
- patch size : 128*128 batch size : 2