T1, T2, FLAIR-Stacked Brain MRI Generation using StyleGAN2


1. T1, T2, FLAIR image
1-1. MRI Parameters
- MRI(자기공명영상)란 인체 내에 있는 원자핵에 외부로부터 에너지를 주어 그 핵에서 발생하는 신호(signal)를 얻어 영상화 하는 것이다.
- MRI에서 주로 이용되는 원자핵은 수소원자핵 내의 양성자(proton)이다.
- 즉, 해당 양성자와 외부 에너지와의 상호작용에 의해 MR 영상에 관련된 대조도를 묘사할 수 있는데, Fat과 Water 두 가지 물질이 기준이 된다.
- Fat의 T1 시간은 Water보다 짧기 때문에 Fat의 종축자화는 RF excitation pulse 후 본래 상태로 회복되는 시간이 물보다 빠르게 된다. (대한자기공명기술학회 MR입문강좌, 2002)
1-2. T1 weighted image
- Fat과 Water 사이에 종축으로 회복되는 T1 시간 차이의 기전을 이용하여 영상화 한 것을 T1 weighted image라고 한다.
- 다른 조직들의 T1 회복시간은 Fat과 Water 사이에 존재한다.
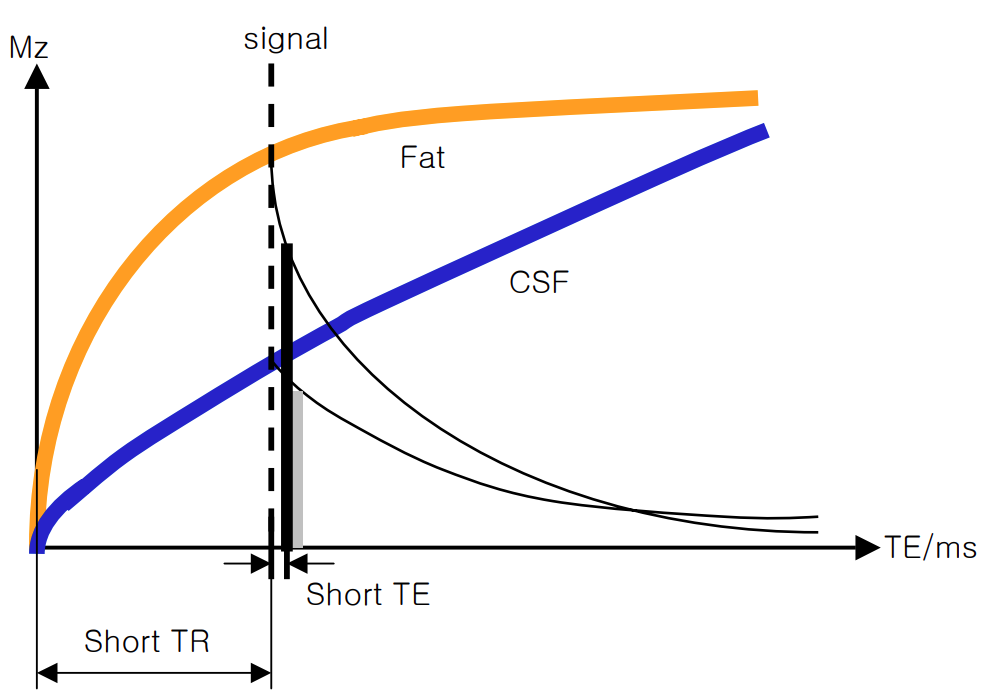
- 정확한 T1 weighted image를 얻기 위해서는 T2 효과가 없는 상태에서 영상의 data를 받아야 하는데, 이런 상황을 만들기 위해 임의적으로 조절하는 것이 TR(Time Repetition) 과 TE(Time Echo) 이다.
- 임상적으로 T1 weighted image는 해부학적 정보에 주로 이용되는 영상으로, 조직간의 대조도를 증가시킬 목적으로 조영제 사용 시 이용되고 있다.
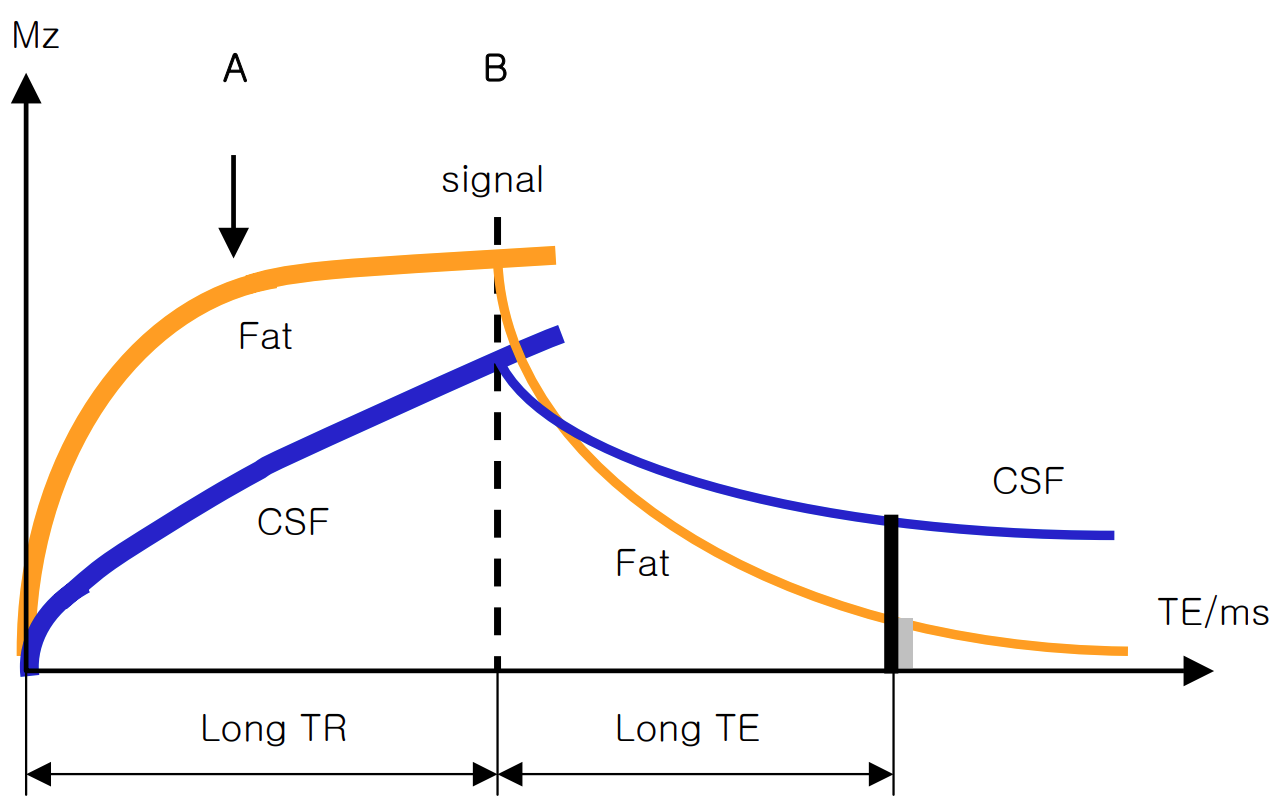
1-3. T2 weighted image
- 우리 인체에 영상을 만들기 위한 필요 에너지 즉, 공명주파수(RF pulse)를 가한 직후 RF pulse를 끊는 순간부터 Fat과 Water의 횡축 자기화는 Spin-spin 상호간의 간섭과 local magnetic field inhomogenity에 의해서 빠르게 dephasing 된다.
- Fat은 물보다 빠르게 dephasing 되고, Water는 서서히 dephasing 되어 일정 시간(80ms) 후에 Fat의 신호는 물보다 작게 보이고, Water의 신호는 크게 보이는데, 이런 영상을 T2 weighted image라고 한다.
- T2 weighted image도 T1 weighted image처럼 TR과 TE 두 factor를 조절하여 영상화 할 수 있다.
- TR과 TE 모두 길게 하고, 임상적으로 병변을 찾는데 이용된다.
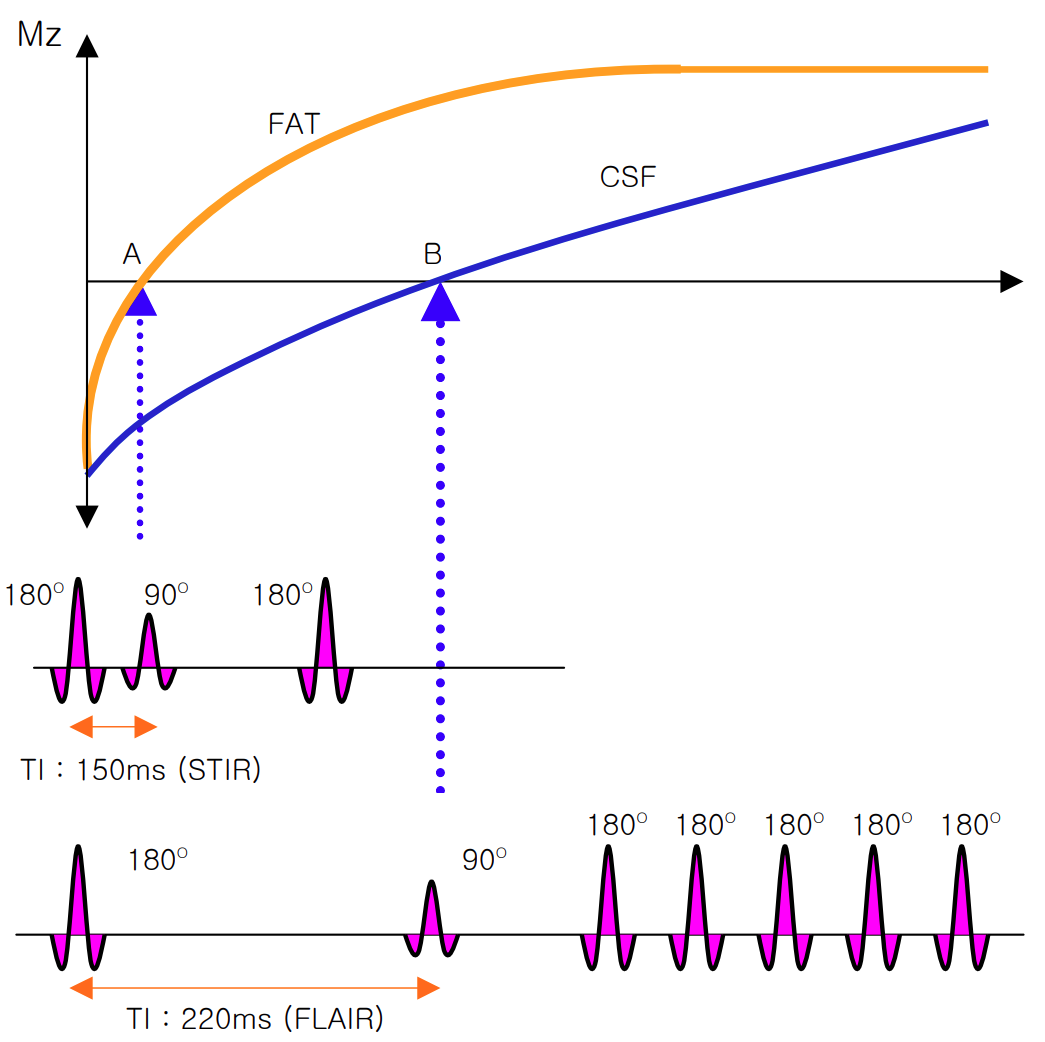
1-4. FLAIR(Flow attenuation IR) image
- 신호를 포착하는 위치에 따라 Fat, Water 분리 영상화를 시킬 수 있는 기법이 있다.
- 종축자기화가 거의 없는 상태 그리고 그때 다른 조직들의 종축자기화는 존재할 때 signal을 얻는 것이 Fat Suppression 방법이다.
- Water의 종축자기화는 거의 없고 다른 조직의 종축자기화는 존재하기 때문에 Signal이 나오는데 이런 방법을 이용하고 있는 것이 FLAIR(Flow attenuation IR) 이라고 한다.
- 이때 TI는 2,000~2,500ms로 상당히 긴 시간이 필요하다.
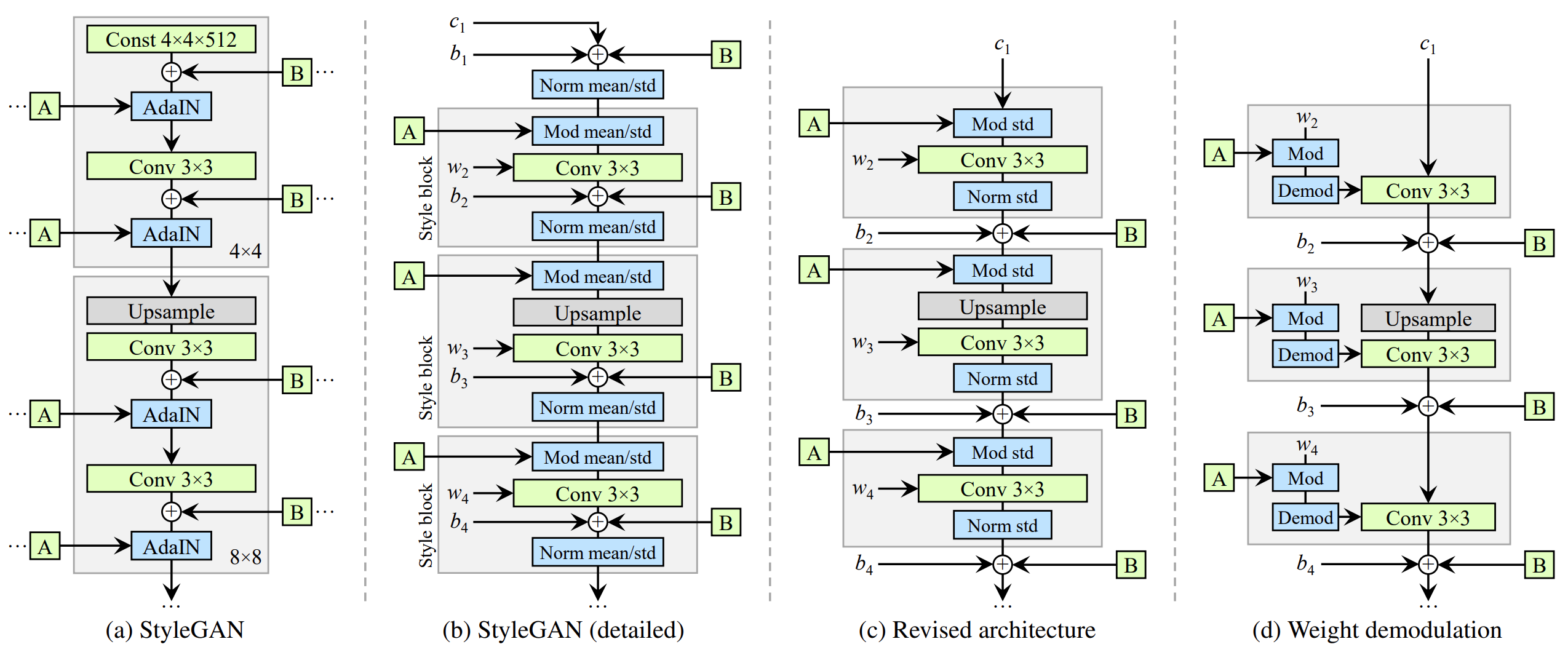
2. StyleGAN2
- StyleGAN의 문제를 분석하고, 모델의 구조와 학습 방법을 개선하였다.
- Generator의 구조 개선
- Generator에 Regularization을 추가하여 더 좋은 image와 latent vector의 대응
- Path lenghth regularization (Perceptual Path Length의 활용)
3. Stacked Brain MRI
- BRATS 데이터셋을 활용하여 T1, T2, FLAIR 영상을 준비하였다.
- T1, T2, FLAIR 이미지는 각각 단일 채널의 이미지이기 때문에, 세 이미지를 채널별로 쌓아서 하나의 RGB 이미지로 만들었다.
- 이렇게 되면 각 채널별로 T1, T2, FLAIR 정보를 담고 있는 Stacked Brain MRI 데이터셋을 만들 수 있다.
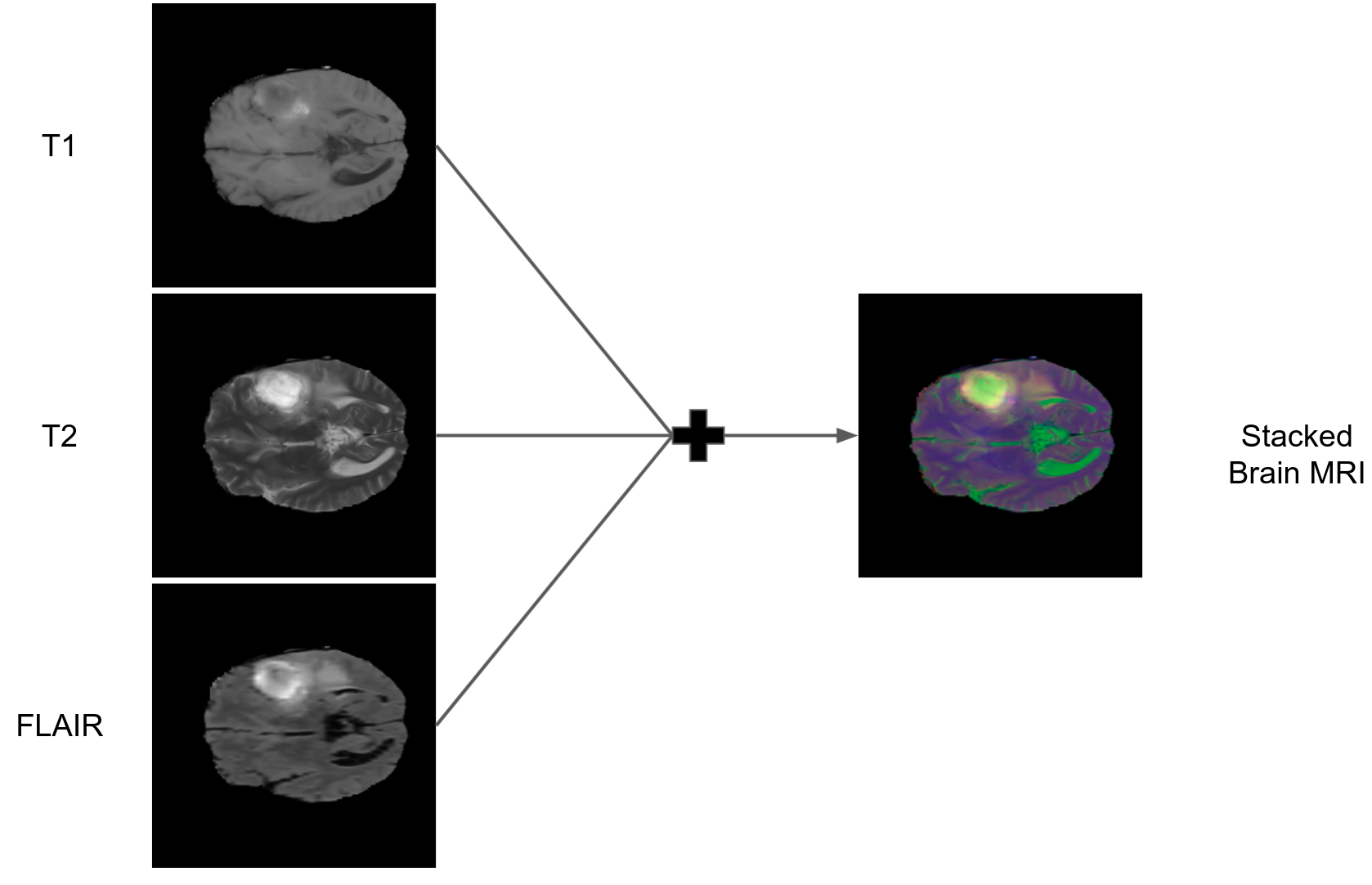
- 위의 방식대로 새롭게 합성된(synthesized) 이미지로 새롭게 데이터셋을 구성함으로써 얻고자 하는 것은, StyleGAN2에 적용을 했을 때, 합성된 이미지의 재생성 뿐만이 아니라, 각 채널 별로 즉, T1, T2, FLAIR 이미지도 잘 생성이 되는지 확인해보고자 하는 목적도 있다.
4. Training
- 위와 같은 방법으로 총 34,100장의 Stacked Brain MRI를 만들어서 학습데이터로 사용하였다.
- 학습은 Scratch로 하였다.
- 학습 데이터의 양은 충분하다고 생각하여 StyleGAN-ADA의 방법은 적용하지 않았다.
- Pre-trained model이나 Discriminator의 freezing도 적용하지 않았다.
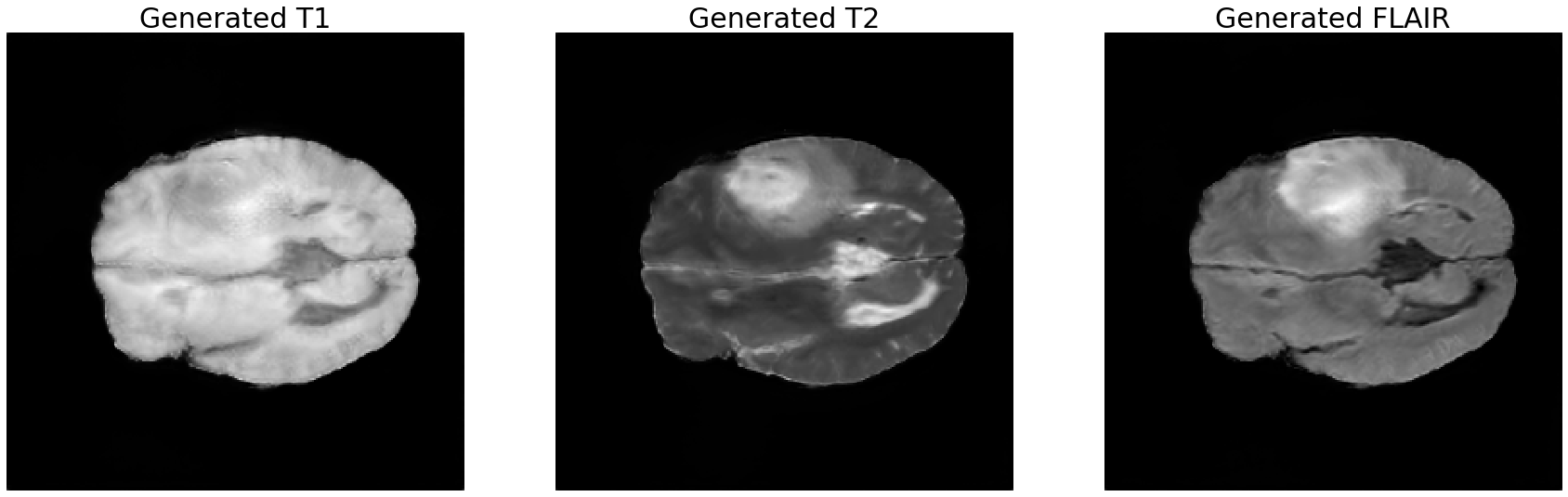
5. Inference
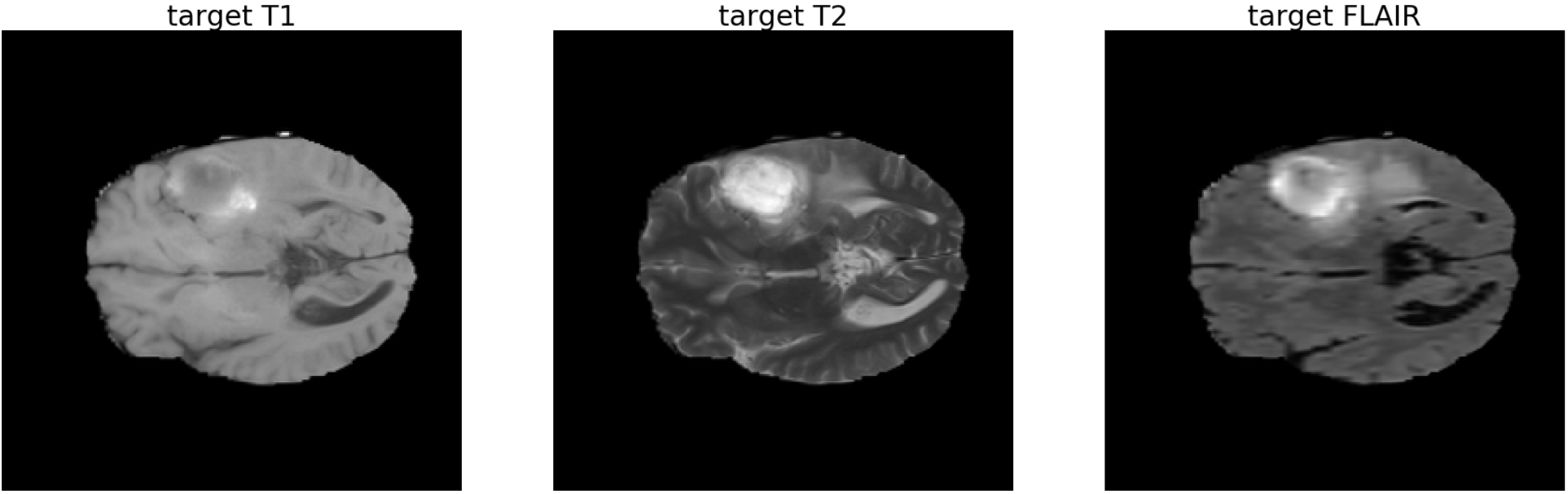
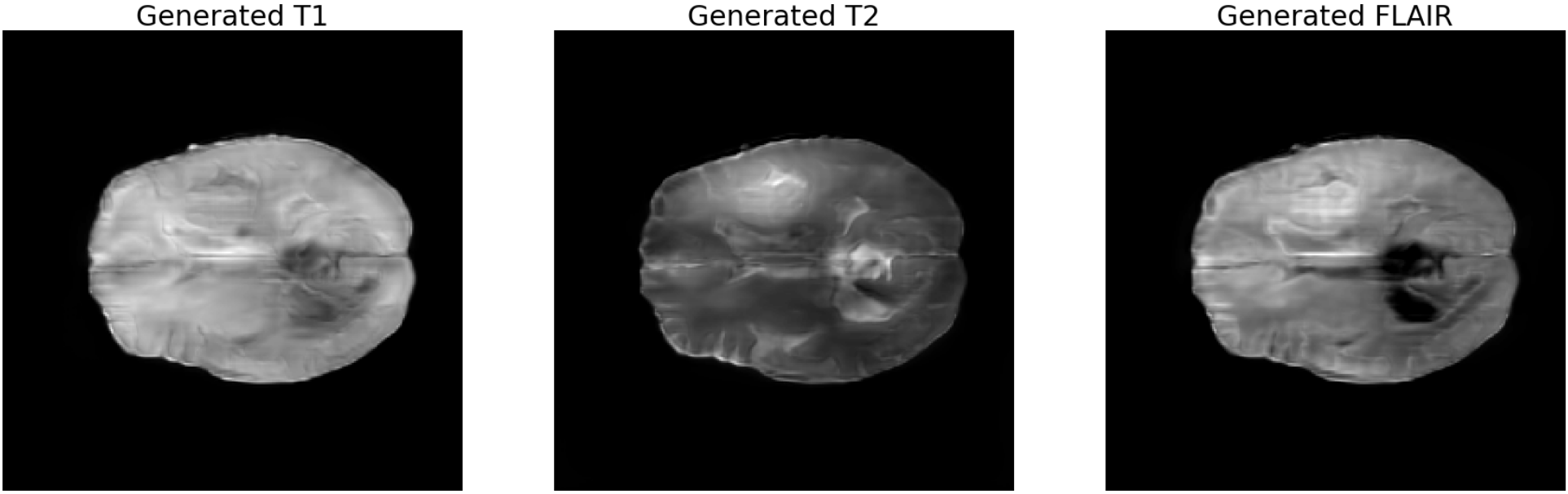
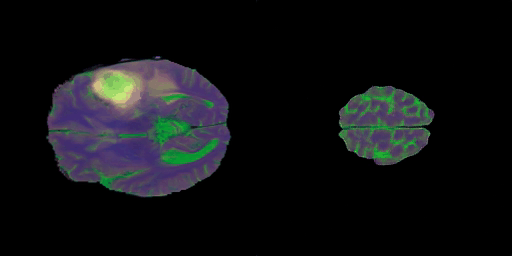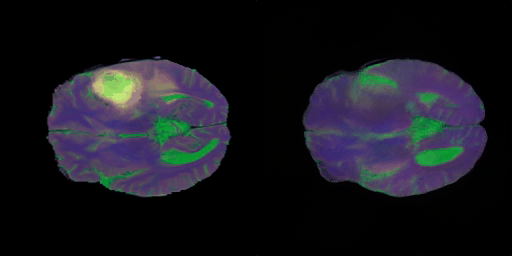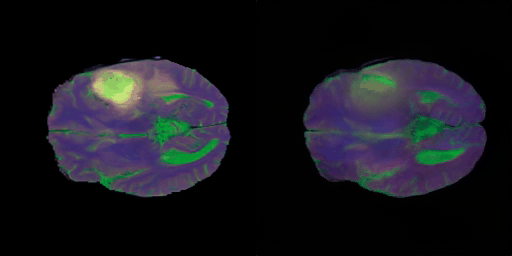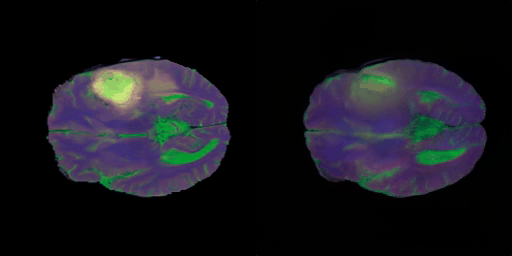
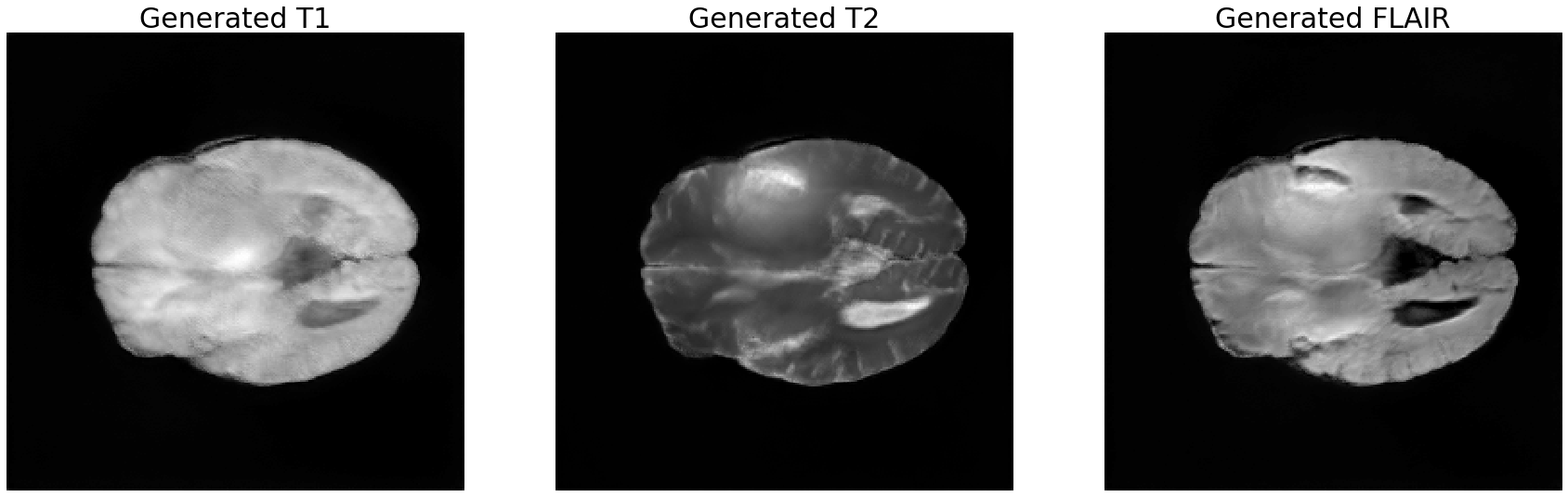
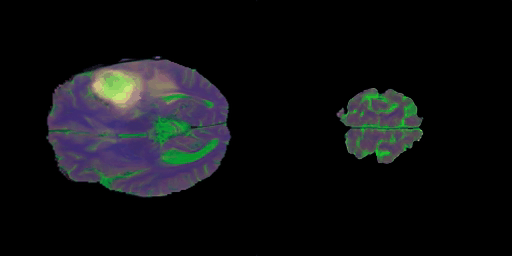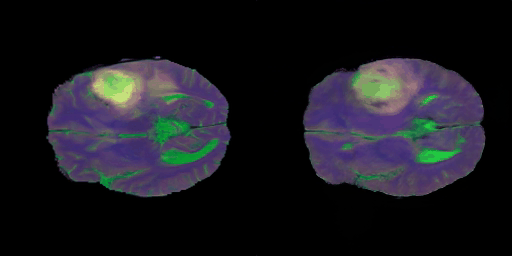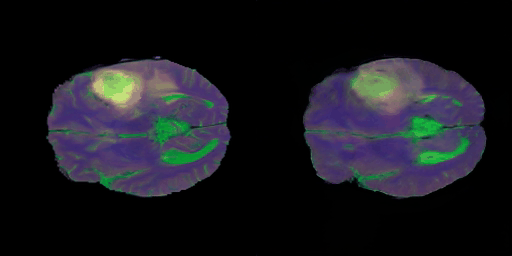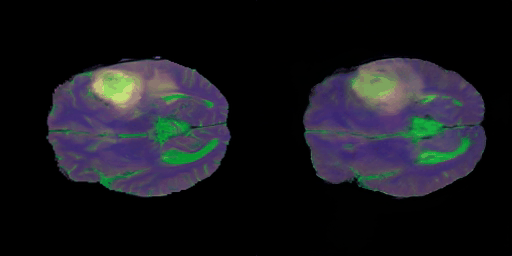
- 타겟 모달리티 이미지
- 차례대로 T1, T2, FLAIR 영상이다.
- 3채널 RGB 영상의 생성이 목적인데, 그 영상의 채널들을 이루는 이미지들이 T1, T2, FLAIR 이므로 타겟 이미지가 되겠다.
- 다음의 inference들에서 보고자 하는 것은, Stacked Brain MRI를 생성할 때, 각 채널에 해당하는 T1, T2, FLAIR 영상도 각각 복원이 잘 되는지에 관한 것이다.
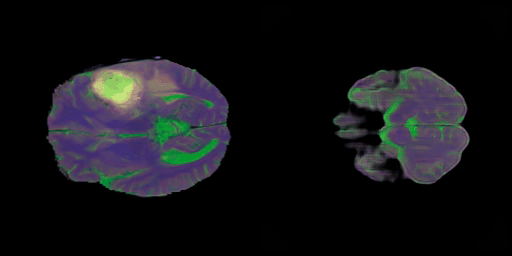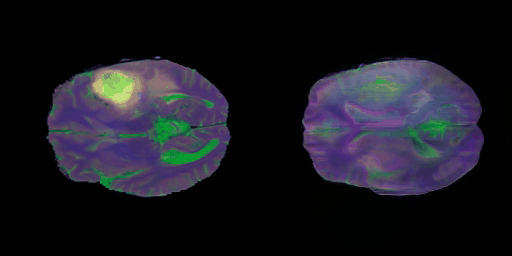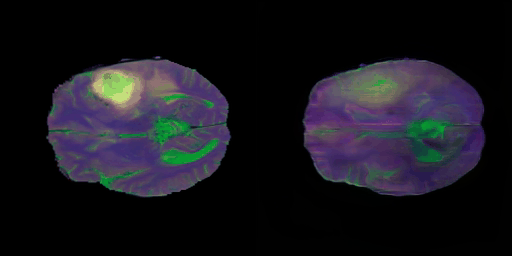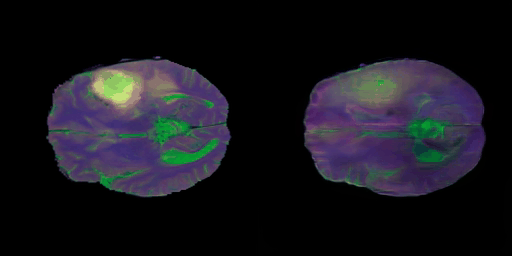
- 학습 초기 단계의 결과
- 2 epoch이 경과한 후의 생성 이미지이다.
- 다음의 그림 7) 에서 보여주는 영상은 타겟 이미지로의 projection 결과이다.
- 그림 8) 에서 영상의 디테일한 부분, 즉 뇌의 영역별 구조보다는 학습 초반 단계이기에 T1, T2, FLAIR 영상이 지니는 명암적 특성에 포커스해본다면, 어느정도는 찾아가는 느낌이다. T1, T2만 보더라도 백색질과 회백질의 구분이 되는 느낌이다.
- 학습 초중반 단계의 결과
- 초반 단계의 학습 결과에 비해서 각 modality별 명암 특성도 잘 찾는 느낌이고 비교적 뇌 구조적인 부분도 잘 생성해가는 느낌이다.
- 학습 중반 단계의 결과
6. 활용방안
- 의료 영상의 특성 상 양질의 데이터를 구하는 것은 자연 이미지에 비해서 난이도가 높다.
- 따라서, 제한된 이미지와 딥러닝을 활용하여 새롭게 이미지를 만들어낼 수 있다면 classification이나 detection, segmentation 등의 솔루션에 도움이 될 수 있다.
- 고성능 모델의 핵심은 단연코 양질의 데이터가 최우선시 되기 때문에 많은 양질의 input data의 중요성은 언제까지나 강조해도 지나치지 않다.
- 따라서, 위와 같은 의료 영상의 생성 기법은 여러 딥러닝 분야에 활용될 수 있다.
참고) 본 게시글은 학습 결과에 따라서 지속적으로 업데이트될 예정입니다.