[PyTorch] 머신러닝, 딥러닝 프로젝트 설계하고 템플릿 구성하기
이번 포스트에서는 머신러닝, 딥러닝 프로젝트에서 효율적인 학습과 추론을 수행하기 위해 템플릿을 구성하는 방법에 대해 소개한다. 따라서, 이전에 소개한 DataLoder 가 템플릿 안에 포함되지만, 자세한 설명은 이전 포스트를 참조하기 바란다. 머신러닝, 딥러닝 프로젝트를 수행함에 있어 정답을 따지기 보다, 이러한 템플릿을 만들게 된 경위(?)는 다음과 같다.
Jupyter는 최대한 사용을 회피하고 싶음.- 정확한 학습(실험)과 추론 결과를 담보하고, 이를 바탕으로 서비스나 솔루션을 개발, 구축하기 위함.
첫번째는 그냥 불편하다 는 개인적인 의견을 포함하고 있다. Jupyter 는 분명, 간단하게 결과를 확인하기에 좋은 도구이고, 프로그래밍을 처음 접하는 사람에게는 매우 유용하다. 데이터 분석이라면 모르겠으나, 머신러닝 또는 딥러닝의 본격적인 프로젝트에 Jupyter 를 도입하기에는 무리가 있다고 생각한다. Jupyter 에서 셀은 위에서 부터 순차적으로 실행되기 때문에, 이전 셀에서 입력된 값이 제대로 전달이 안되거나, 변수와 메서드가 뒤섞여서 커널을 처음부터 다시 실행하는 경우는 흔히 겪게된다.
바로 이런 점이 두번째 항목과 관련있는데, 파라미터를 계속 바꿔가면서 더 좋은 모델을 만들때는, 모델과 파라미터의 버전을 어느순간 일치시키기 힘들어진다. (파라미터를 바꿀 때 마다 메모해 놓는것도 귀찮고, 사람이 개입하기 때문에 실수가 발생할 우려도 있다. 무엇보다, 과거 모델과 현재 모델을 비교하는 A/B 테스트를 하려면, 과거 학습시에 썼던 파라미터가 보존되어 있어야한다. 실험할 때마다 Jupyter notebook 을 카피해 놓을 자신이 있는가?)
포스트에서는 일부 코드가 생략되어 있기 때문에, 전체 예시를 여기에서 참조하기 바란다.
템플릿 전체 소개
소개할 템플릿은 필자의 매우 개인적인 경험에 의한 패턴이고, 복잡하거나 특이한 딥러닝과 관련된 소스코드가 이런 템플릿으로 구현이 가능할지는 아직은 경험이 더 필요할지 모르겠다. (약간 복잡한 multi-class classifier 와 3D-alpha-WGAN-GP 는 리팩터링 가능했다.) 전체적인 생김새는 다음과 같이 매우 간단한 구조임을 알 수 있다.
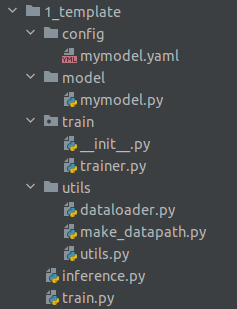
먼저, config, model, train(=package), utils 폴더와 같은 위치에 모델을 학습하는 메인함수가 담긴 train.py 와 추론과정에서의 메인함수가 담긴 inference.py 를 생성한다. 앞서언급했듯이, utils 이하의 dataloader.py 는 설명을 생략한다.
모델 클래스와 학습 루프
먼저 model 과 train 이하에 대해 설명한다. 머신러닝과 딥러닝 프로젝트를 접할때, 좋은 모델은 이미 널리 쓰이고 있기 때문에, mymodel.py 에는 구현된 모델의 클래스를 따로 격리시켜 놓았다.
이번 예시에서는, 실험에 사용하고 싶은 모델을, 추후에 설명할 yaml 파일로 컨트롤 하고 싶다는 상황을 가정하고, 위와 같이 model_dict 에 두 종류의 모델을 넣어 두었다.
다음으로, 학습 루프는 길고 복잡한 관계로, 일부 코드와 전체 구조만 소개한다.
많은 부분을 생략했지만, 학습 루프를 어떻게 구현했는가는 중요하지 않다. 만약 GAN 을 학습시킨다면, 코드는 더 길어지고 이보다 복잡한 구조가 될 것이므로, 상황에 따라 위의 클래스는 달라진다. 포인트는, 어떤 학습 루프를 구현하더라도, 다음에 설명할 yaml 을 사용자의 환경에서 학습이 시작되기전에 먼저 저장해주고, 학습이 최종적으로 끝나면, 완성된 가중치를 yaml 파일이 위치한 곳에 같이 저장해주는 설계이다.
yaml 설정 파일
위에서 생략한 두가지 함수, _save_config_file 과 _copy_to_experiment_dir 가 학습에 필요한 파라미터를 담고 있는 yaml 파일과, 학습을 통해 나온 가중치 파일을 항상 세트로 관리해주는 역할을 한다. 먼저, yaml 파일의 구조를 보면 다음과 같다.
가장 위부터 5개의 파라미터는 학습과 추론에서, 프로젝트 특성상 변경이 자주 일어나는 파라미터라고 생각하여 따로 빼 놓은 것들이다. inference_device 는 추론을 수행하는 메인함수에서만 작용하는 변수이고, cpu 로 추론해야 하는 상황에서는 cpu 로 바꿔주도록 메인함수를 구현했다(cpu 추론은 실제 프로젝트에서 자주 발생함). 따라서, 학습 과정과는 무관한 파라미터가 있어도 상관없다. 마지막 줄의 base_model 은 앞서 설명했듯이, my_model_class_1 모델을 사용자가 직접 설정했고, model 클래스에서 확인해보면, 이는 resnet50 였음을 확인할 수 있다.
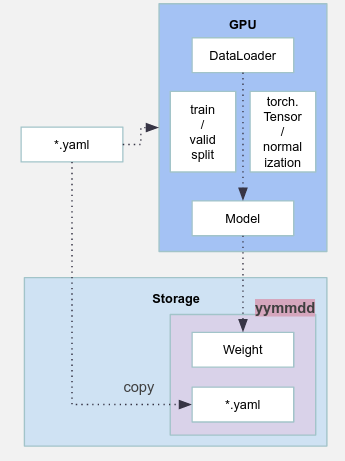
다시 한번 강조하지만, 이 설정 파일로부터 학습이 끝난 모델 가중치는 지구상에서 유일하다. 완전히 똑같은 설정파일로 학습을 한번 더 실행해도 같은 가중치는 생성되지 않는다고 엄밀하게 접근하는 것이 안전하다(이론상 같은 가중치이냐 아니냐를 따지자는 것이 아니라, 가중치를 직접 눈으로 확인할 수 없기 때문이다. 사실은, 사용자가 실수로 같은 설정파일로 학습해버렸을 때를 대비해, _copy_to_experimet_dir 함수에서, 모델과 yaml 파일을 timestamp 디렉토리로 한번 더 카피하게 끔 구현했다).
학습 결과 및 결론
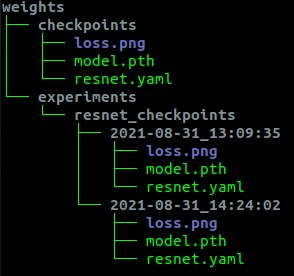
학습과 추론을 실행하는 메인함수는 설명을 생략하고, 전체 코드를 참조하기 바란다. 이 템플릿 안에는 모델을 효율적으로 관리하기 위한 설계가 숨어있었는데, 실제 이 구조로 분류 학습을 진행하고 나온 모델과 파라미터들이 어떻게 관리되는지 아래 그림에서 확인할 수 있다.
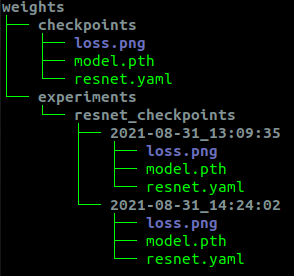
예시 코드를 살펴보면, 최초 학습, 또는 가장 최근 학습으로 나온 가중치와 설정파일은 무조건 checkpoints 로 저장되고, 이후 학습이 끝날 때 마다, 기존의 최신 파일이 experiments 이하로 timestamp 폴더가 생성되며 저장되고, 다시한번 가장 최신 학습으로 인한 파일은 checkpoints 로 덮어 씌워진다.
하나 더 설명하자면, yaml 파일에서 resume 이란 항목이 있었다. 이 템플릿에는 다음과 같이 한가지 더 중요한 설계가 있다.
- resume: None 인 경우 -
train.py에서는 학습을 scratch 로 실행하여, 새로운 가중치 파일을 생성한다.inference.py에서는 가장 최근 가중치와yaml파일로 추론을 수행한다. - resume: "yyyy-mm-dd_hh:mm:ss" 인 경우 -
train.py에서는 해당 과거 가중치와yaml파일을 읽어 와서 학습을 이어나간다(즉, checkpoint).inference.py는 해당 과거 가중치와yaml파일을 읽어와 추론을 수행한다.
이와 같은 설계도 역시 중요하다. 학습이 끝나자 마자 바로 모델을 테스트하기에는 첫번째와 같은 워크플로우를 취하기도 하고, 맨 처음 말했던 A/B 테스트를 하려면 과거 모델의 추론결과를 비교해야 하므로, 두번째 항목과 같은 워크플로우도 필요하기 때문이다(설계는 결국 프로젝트의 품질로도 이어질 수 있다!!).
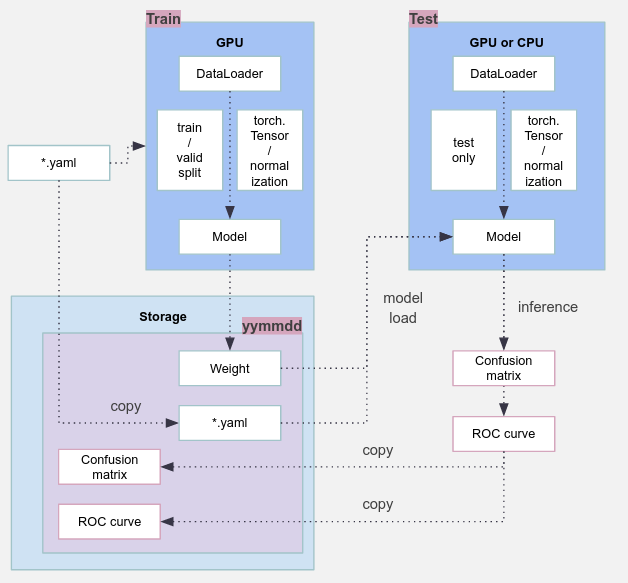
많은 부분을 생략했지만, 프로젝트마다 공통된 워크플로우는 각자 사정에 맞게 설계를 해 두면 편하기도 할 뿐더러, 모델의 관리도 쉬워지고, 프로젝트를 성공적으로 마칠수도 있을 것이다. 더 많은 머신러닝, 딥러닝 프로젝트를 이 템플릿에 담아보면서, 조금씩 수정해 나가면 개발자와의 협업도 수월해 질 것으로 생각한다.
(오타나 질문, 기타 의견은 smha@promedius.ai 로 부탁드립니다.)