효율적인 Anomaly Detection 방법[f-AnoGAN vs MemAE]

![효율적인 Anomaly Detection 방법[f-AnoGAN vs MemAE]](/content/images/size/w2000/2021/01/MemAE_figure-1.png)
Unsupervised Learning 방법으로 GAN을 이용한 Anomaly Detection 방법 중 Encoder을 이용한 f-AnoGAN 방법이 있습니다. 이 방법은 효율적으로 정상화 다른 결함 부분을 검출 하지만 미세한 결함은 제대로 검출하기 힘들다는 한계가 있습니다.
본 글에서는 f-AnoGAN의 특징과 그 단점에 대해 간략히 소개하고 그 해결책에 대한 내용을 간단하게 정리해보기 위한 글 입니다.
비교할 논문을 아래와 두 논문입니다.
f-AnoGAN
- 참고 링크: Fast Unsupervised Anomaly Detection with GAN
- Github tutorial: Link
f-AnoGAN의 학습 방법은 GAN 학습, Encoder 학습으로 총 2가지 step으로 학습이 진행됩니다.
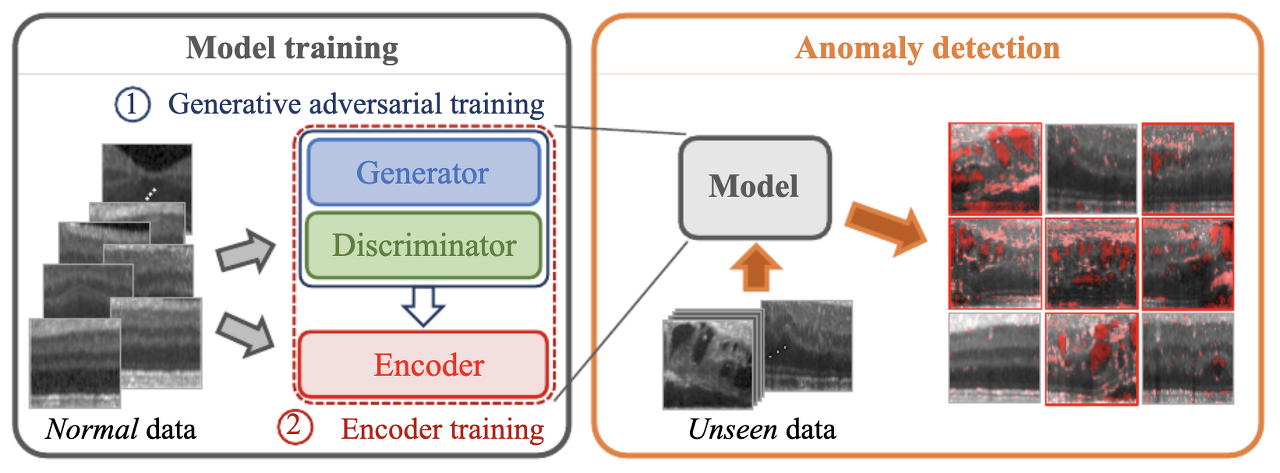
GAN 학습
정상 데이터로 GAN 학습을 진행합니다. GAN이 잘 학습 되었다면 정상 데이터의 학습 분포를 기반으로 학습이 이루어져 Generator가 이미지를 생성할 때 정상 이미지만을 생성할 가능성이 매우 높아집니다.
Encoder 학습
GAN을 잘 학습한 후 입력된 데이터의 Latent Space Mapping을 위한 Encoder 학습을 추가적으로 진행합니다. 이떄 GAN의 weight는 더이상 update 되지 않게 고정시켜 줍니다.
TEST 과정 중 정상인지 비정상인지 궁금한 query data을 GAN에 입력하면 Generator는 query data와 전혀 관계 없는 정상 데이터를 생성하게 됩니다. 이를 방지하기 위해 Encoder 학습을 통한 Latent Space mapping을 진행한 후 query data을 Encoder에 넣어주면 query data의 특징이 추출된 \( E(x)\)을 얻게 됩니다. \( E(x)\)을 Generator에 입력시켜 주면 query data의 형태, 질감, 모양과 동일하지만 결함있는 부분을 제거한 정상 이미지인 \( G(E(x))\)을 생성하게 됩니다.
이로써 query data \( x\)와 생성 데이터 \( G(E(x))\)의 차이를 구한 후 Anomaly Detection을 수행합니다.
단점
AutoEncoder을 이용한 Anomaly Detection은 AutoEncoder 특성상 일반화(Generalization)을 너무 잘해서 정상만 생성하도록 해야하는데 비정상까지 재구성 하게 되어 미세한 결함을 제대로 찾기 힘들다는 단점이 존재합니다.
해결책
AutoEncoder의 일반화가 너무 잘되 결함까지 포함해서 생성할 수 있다는 단점을 극복하기 위한 해결책으로 memory module을 사용해서 AutoEncoder을 augment(보강)는 방법인 MemAE(memory-augmented autoencoder)을 사용합니다.
MemAE
MemAE의 핵심 내용은 AutoEncoder가 너무 General하게 학습되는 경우가 발생하여 정상 뿐만 아니라 간혼 비정상의 결함 부분까지 포함하여 생성하게 된다는 단점이 존재합니다. 이를 해결하기 위해 정상 데이터를 Encoding할 때 정상 데이터에 대한 memory을 얻은 후 이를 기반으로 해서 정상 데이터를 생성하는 방법입니다.
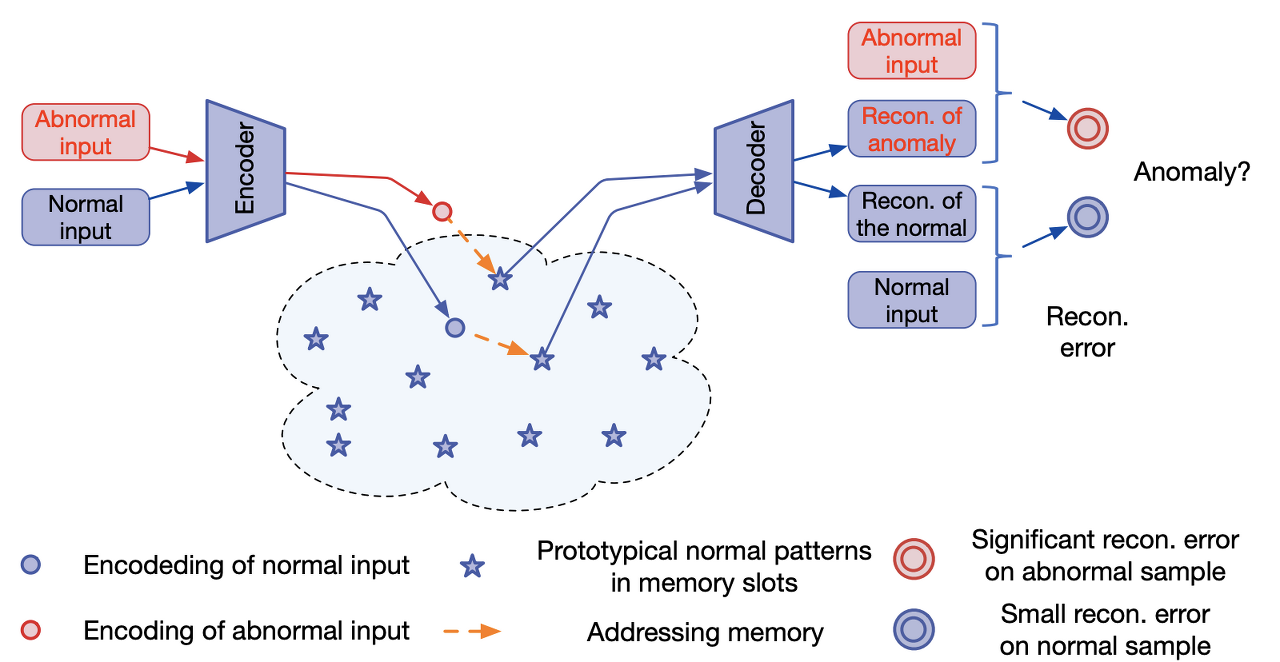
학습 단계에서 memory는 정상 데이터에 가장 관련성이 높은 momory items을 검색하여 데이터를 생성(재구성)하게 됩니다.
테스트 단계에서 정상 데이터에 가장 관련 이 높은 memory을 고정시킨 후 query data가 입력으로 주어지면 query data을 기반으로한 정상 데이터를 memory 기록으로부터 검색을한 후 이를 기반으로 생성(재구성)이 이루어지는 효율적인 아이디어 입니다.
본 포스팅에서 소개한 방법론을 기반으로 추후에 리뷰할 논문 리스트 입니다.
◽️ MemAE
◽️ TrustMAE