PyTorch 데이터로더 이해하기 - Part 2

이전 Part 1 에서 PyTorch 를 활용하여 나만의 DataLoader 를 작성하는 가장 기본적인 방법들에 대해 알아 보았다면, 이번 포스트에서는 그것들을 응용한 나만의 DataLoader 를 커스터마이징한 사례에 대해 소개하고자 한다.
SimCLR
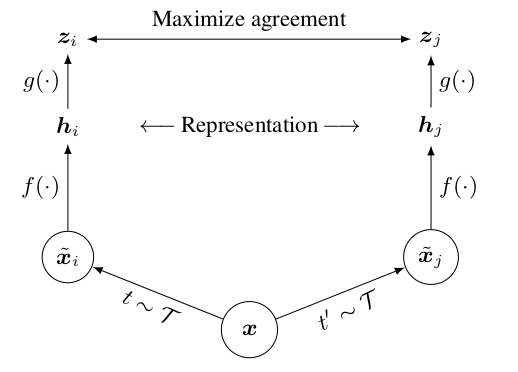
최근에 self-supervised learning 과 관련하여 몇가지 논문들이 주목받고 있는데, 2020년 상반기에 업로드된 SimCLR 이 다른 여러 self-supervised methods 가운데 좋은 성능을 낸다는 것이 입증되었다고 한다. SimCLR 은 간단히 말하자면, 이미지를 랜덤한 방식으로 augmentation을 독립적으로 진행, feature vector 를 추출하고, 이 vector space 상에서 NT-Xent 손실함수를 통해 비슷한 이미지는 가깝게, 다른 이미지는 서로 멀리 떨어지도록 학습하는 컨셉을 가지고 있다. 원 논문에서 발췌한 Figure 를 보면 전체적인 학습의 컨셉은 다음과 같다.
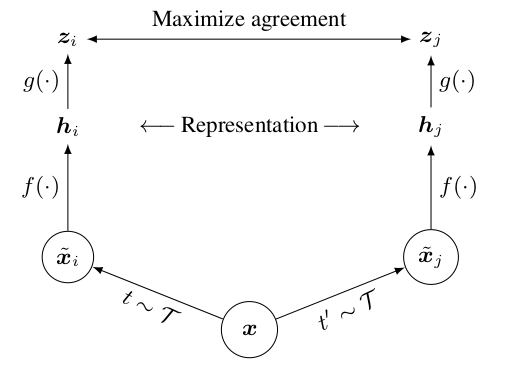
SimCLR 자체가 오래된 내용이 아니다보니 PyTorch 로 구현된 사례들이 그리 많지 않았는데, Thalles Silva 님의 블로그에 아주 정리가 잘 되어있었다. SimCLR & SimCLR v2 의 전체적인 내용은 따로 다루기로 하고, 우선 실제 학습을 위한 준비에 초점을 두고 Thalles Silva 님의 구현 방식에 대해 리뷰, 커스터마이징 해보기로 하겠다.
아래로 넘기기 전에 wrapper 클래스를 어떻게 구현하였는지, 위 그림과 비교하여 코드를 한번 훑어보기를 권장한다.
Dataset Wrapper
전체 wrapper 클래스에서도 최종적으로 사용자가 훈련 루프에서 사용하게 될 ‘get_data_loaders’ 의 구조에 주목하여, 관련된 메서드로 어떤 것들이 구현되어 있는지 파악해 볼 것이다. 대략적인 흐름은 데이터셋을 두개의 파이프라인에 태워 augmentation 을 진행하고, DataLoader 안에 데이터셋의 mini-batch 를 격납시키는 처리로 예상되는데, 차근차근 그 구조를 뜯어보도록 하자.
1. get_data_loaders
SimCLR 은 훈련 루프를 구현하게 되면 “(x_is, x_js), _” 와 같은 형식으로 mini-batch 를 반환해주는 DataLoader 가 필요하게 된다. 튜플은 서로 다른 파이프라인을 타고 augmentation 이 진행된 데이터이고, 뒤의 언더바는 unlabeled 를 나타내는데, 이하의 함수가 반환하는 train_loader & valid_loader 가 이 구조를 내포하고 있다.
SimCLR 의 원 논문은 ImageNet 데이터셋을 사용하였지만 여기서는 STL-10 을 사용하고 있다. 구지 이유에 대해 추측해 보자면 ImageNet 보다 컴팩트 하면서도 labeled, unlabeled 데이터를 다양하게 섞어서 사용하는게 가능하기 때문이 아닐까 한다. 정확히는 비지도 학습 방식을 고려하는 것이 맞지만, split 옵션은 추후 자료구조 탐색을 위해 원 저자와 똑같이 ‘train+unlabeled’ 로 고정하도록 한다.
2. _get_simclr_pipeline_transform
원 논문에서는 각각의 파이프라인에 대하여 ImageNet 데이터셋을 다음과 같은 방식을 취해 augmentation 하였다.
- Random crop & Resize
- Random color distortions
- Random Gaussian blur
‘_get_simclr_pipeline_transform’ 은 augmentation 을 포함하고 있고, 이전 포스트에서 설명한 바와 같이 transforms.Compose 를 이용하여 간단하게 구현할 수 있다. (GaussianBlur 는 opencv-python 으로만 구현됨. 본문에서는 생략.)
공식 API document 를 통해 유추해 볼 수 있듯이, RandomResizedCrop 의 input_shape 는 STL-10 데이터셋의 (width, height) 를 의미하는데, 랜덤하게 이미지의 일부분을 crop 한 뒤 원래의 shape 크기로 늘리는 resizing 을 수행한다는 의미이다. Colorjitter 안의 s 파라미터와 함께 이러한 인자는 따로 빼놓고 작업하는 것이 수월할 것 이다.
3. SimCLRDataTransform
다음과 같은 클래스를 Dataset wrapper 클래스와 별도로 구분하여 작성하는 것이 포인트이다.
이 부분은 생성자의 transform 이 ‘_get_simclr_pipeline_transform’ 처럼 별도로 구현되었다는 점과, (xi, xj) 와 같이 서로 다른 transform 을 튜플 형식으로 반환한다는 점을 제외하면, Part 1 의 ImgTransform 클래스와 별반 다를게 없다.
4. get_train_validation_data_loaders
다시 Dataset wrapper 로 돌아와서, ‘get_train_validation_data_loader’ 에서는 STL-10 데이터셋을 다음과 같이 DataLoader 에 격납시킨다. 당연하지만, shuffle 옵션을 True 로 설정하게 되면, 매 epoch 마다 데이터를 뒤섞기 때문에 SubsetRandomSampler 와 같이 sampler 를 직접 구현해서 사용하는 경우에는 False(=default) 로 주어야 한다. 이와 관련하여 torch.utils.data 문서를 참조하도록 하자.
SimCLR 을 STL-10 데이터셋으로 학습하기 위한 wrapper 클래스는 생성자와 앞서 생략한 GaussianBlur 를 포함하여 레포지토리에 올려두었으니 참조 바란다.
Tensor structure
본격적으로 나만의 SimCLR 을 학습하기 위한 커스터마이징을 진행하기 전에, 앞서 구현된 wrapper 가 반환하는 자료구조를 간단하게 확인하고 넘어가야 할 필요가 있다. 다음은 for 문을 이용하여 train_loader 가 반환하는 데이터의 구조를 직접 출력하여 본 결과이다.
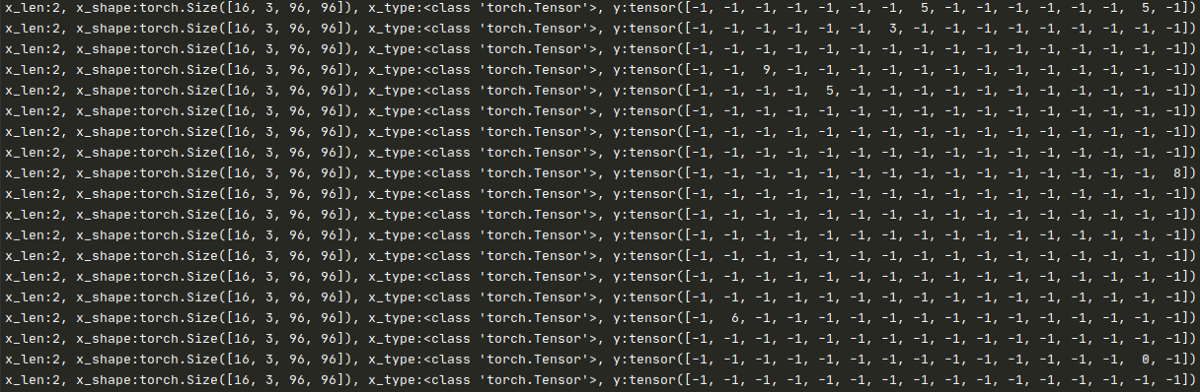
사용한 코드는 언제나처럼 “for x, y in train_loader” 인데, 여기서는 총 4가지
- x_len : augmentation 파이프라인 수
- x_shape : 각 mini-batch 별 shape 연산
- x_type : 각 nimi-batch 별 type 연산
- y : 라벨 관련 정보
에 관한 구조를 알아보았다. Transform 의 파이프라인이 여러개가 아닌 일반적인 경우라면 바로 x.shape 를 통해 [batch_size, channel, width, height] 가 확인 가능하지만, 첫번째 항목의 파이프라인 수가 리스트 구조를 반환하기 때문에 x[0] 또는 x[1] 와 같이 파이프라인을 지정한 뒤에서야 해당 자료구조가 출력이 가능하다는 점에 주의하자.
Torchvision — datasets.STL10
SimCLR 은 pre-trained 모델을 만들기 위해 unsupervised task-agnostic training 을 진행하는 것이 기본이기 때문에, 지금까지 살펴본 wrapper 를 그대로 사용하기에는 약간의 제약사항이 있다. 다음은 torchvision.datasets.STL10 을 직접 분석하여 알아낸 결과 중 일부이다.
1. Unlabeled dataset 일 것
나만의 데이터셋으로 모델을 학습시키기 위해서는 위 자료구조의 마지막의 라벨 관련 정보가 특히 중요하다. 현재는 위와 같이 군데군데 -1 이 아닌 다른 숫자가 섞여 있는데, ‘get_data_loader’ 에서 torchvision 의 datasets.STL10 의 split 옵션을 train+unlabeled 로 사용하였기 때문에, 약 5천장의 라벨 정보가 포함되어 있는 것이다. 옵션을 unlabeled 로 바꾸어 라벨 정보를 출력해보면 모두 -1 로 바뀌어 있는 것을 확인할 수 있는데, 프로젝트에서 사용할 unlabeled 데이터셋역시 라벨값이 -1 이 나오도록 wrapper 를 구성해야 할 것이다. datasets.STL10 에서는 이 부분이 다음처럼 구현되어 있었다.
split 옵션이 unlabeled 일때만 골라서 보면, 강제로 데이터 길이만큼 -1 을 할당하고 있다.
2. Binary 형식이 아닌 일반적인 img 확장자를 지원할 것
또 한가지 문제점은, bin 형태의 데이터를 torchvision 의 datasets.STL10 에서 array 를 reshape 하여 읽어오는 방식으로 데이터를 취득하고 있다는 것이다. png 나 jpeg 형태의 데이터가 프로젝트에서 쓰인다면, 이 부분 역시 고쳐야할 점이다. (Part 1 에서 이미 다룬내용이다.)
Customizing Dataset Wrapper
설명은 길었지만, 앞에서 본 Dataset Wrapper 와 구조는 동일하게 가져가기 때문에 사실 고칠점은 별로 없다. 동일하게 STL-10 unlabeled 100,000 장분량의 binary 를 모두 jpeg 파일로 변환, 저장한 뒤 사용하여 실제 이미지의 shape 만 변경하면 동일하게 적용 가능하도록 wrapper 를 구성하였다.
변환하여 저장한 이미지 데이터가 “./data/unlabeled” 에 모두 저장되어있다고 가정하면, 언제나처럼 데이터 파일 리스트와 데이터셋 클래스를 기계적으로 작성한다.
구현된 MyDataset 클래스와 make_datapath_list 는 기존의 ‘get_data_loaders’ 에서 torchvision.datasets.STL10 역할을 완전히 대체하는 것이 가능하다.
나머지는 따로 수정하지 않아도 SimCLR 학습이 가능한 것을 확인하였으니, 아마 앞으로도 비슷한 구조를 가지는 BYOL 이나 기타 method 들에 대해 유용한 wrapper 가 될 것 같다.
 Seungmin Ha
Seungmin Ha